
![]() 愿景:"让编程不再难学,让技术与生活更加有趣"
愿景:"让编程不再难学,让技术与生活更加有趣"
更多架构课程请访问 xdclass.net
第一章 小滴课堂-新一代流式计算框架Flink课程大纲介绍
第1集 玩转新一代流式计算框架Flink课程介绍
简介:玩转新一代流式计算框架Flink课程介绍
- 课程介绍
小滴课堂-全新录制的后端+大数据视频,从0到1讲解流式计算框架Flink1.13 ,掌握Flink核心概念和应用场景,包括大数据扫盲贴,离线/实时/批量/流式计算划分;从JDK8的Stream流处理延伸到,为啥用Flink,再讲全链路知识点解析,Source—>Transformation->Sink多种案例实战从零讲解Flink整体实战:JobManager、TaskManager、TaskSolt、OperatorChain等核心概念和应用场景全套视频采用多个案例进行实操讲解对应的知识点应用,从实际需求出发更容易掌握。核心基础玩转多种Source实战:SocketStream、Kafka、RichParallelSourceFunction等多种数据来源中间转换实战:Map、FlatMap、Rich相关算子应用、Filter、Max等多种Operator转换操作结果输出实战:Sink输出Redis存储、Mysql、Kafka、自定义Sink组件等多种Sink处理进阶高级:KeyBy分组聚合、滑动时间窗、滚动时间窗实战多个业务需求多种聚合函数实战Reduce/aggregate/ProcessWindowFunction实战多种时间语义介绍、迟到乱序数据处理+Watermark应用和侧输出流实战State状态存储和Checkpoint检查点配置、模拟MaxBy算子功能实战Flink CEP复杂事件处理检测,实战恶意登录高级功能打包部署和综合项目实战阿里云 ECS Linux服务器部署Flink Standalon+项目打包插件和配置实战Docker-Compose集群部署Flink+SessionCluster+PerJob+Application模式解析WebUI并行度案例测试Parallelism+TaskSolt核心概念和应用项目实战:开发一个监控告警案例(类似nginx访问日志)滑动时间窗统计各个接口的访问量、各个状态码次数、CEP告警检测
讲课前我一直再思考一个问题
- 如何让大家零基础去掌握Flink、记住该记住的内容,Flink内容和API太多太多
- 从简单的JDK8的Stream开始,抛出问题,怎么解决,引出Flink强大之处
- 业务需求出发,怎么利用Flink快速的解决和流程化
- 课程80多集,每集10~20分钟不等,总时长15小时左右
- 一天学习3小时,操作3小时,一周足够掌握Flink 核心技术+案例实战+部署

为什么要学习Flink流式计算框架
多数互联网公司里面用的技术栈,打造实时监控、数仓、推荐、画像系统技术栈
流式计算框架中最火爆的技术,在多数互联网公司中,Flink占有率很高,流式计算框架领域领头羊
中大型互联网公司等基本都离不开Flink
可以作为公司内部培训技术分享必备知识
谁在用Flink(大厂基本都在用,所以重要程度知道吧,想进一二线大厂的同学)
学后水平
- 从0到1讲解新版流式计算框架Flink,掌握Flink核心概念和应用场景
- 掌握大数据基础技术栈,离线/实时/批量/流式计算划分
- 掌握Flink整体架构JobManager、TaskManager、TaskSolt、OperatorChain等
- 全链路知识点解析,Source—>Transformation->Sink多种案例实战
- 玩转多种Source实战,中间转换算子处理,Sink结果输出
- Flink链接Kafka、Redis、Mysql等多种数据源实操读取和输出
【进阶高级】
- KeyBy分组聚合、滑动时间窗、滚动时间窗实战多个业务需求
- 多种聚合函数实战Reduce/aggregate/ProcessWindowFunction实战
- 多种时间语义介绍、迟到乱序数据处理+Watermark应用和侧输出流实战
- State状态存储和Checkpoint检查点配置、模拟MaxBy算子功能实战
- Flink CEP复杂事件处理检测,实战恶意登录高级功能
【打包部署和综合项目实战】
阿里云 ECS Linux服务器部署Flink Standalon+项目打包插件和配置实战
Docker-Compose集群部署Flink+SessionCluster+PerJob+Application模式解析
WebUI并行度案例测试Parallelism+TaskSolt核心概念和应用
综合案例实战
- 开发一个监控告警项目,乱序延迟数据处理和复杂聚合统计
- 滑动时间窗统计各个接口的访问量、各个状态码次数、CEP告警检测
贯穿全套视频掌握Flink常见面试题+大数据学习路线规划
大数据工程师和后端工程师的恩恩怨怨
你会的我也会,我会的你不一定会,你会的我也不一定会
技术栈交集大
- Javase、javaweb、springboot、linux、docker、redis、kafak、flink、hbase 等等

适合人群
- 高级后端工程师、运维工程师
- 大数据工程师、数据分析工程师
- 互联网公司技术经理、CTO 必备技术栈
课程技术技术栈和环境说明
- Flink版本:1.13~1.14
- Scala版本:2.12
- Maven + IDEA旗舰版 + JDK8 或 JDK11(课程是纯java开发)
学习形式
- 视频讲解 + 文字笔记 + 原理分析 + 交互流程图
- 配套源码 + 笔记 + 专属技术群答疑( 我答疑,联系客服进群)
- 进技术群还有加餐内容(多种高可用集群搭建+大厂面试题) , 大厂内推资源、文档大礼包等
- 课程有配套的源码,在每章-每集的资料里面,如果没用到代码就不保存
- 只要是我的课程和项目-我会一直维护下去,大家不用担心!!!
第2集 新一代流式计算框架Flink课程大纲速览
简介:新一代流式计算框架Flink课程大纲速览
课程效果演示和安装包

课程学前基础
Java基础即可,其他可以后补
- Linux、Kafka、Redis、Mysql、Docker
PS:不会上面的基础也没关系, 这些专题我们都有课程,【联系我们客服】购买即可,且是刚录制的新版课程
目录大纲浏览
学习寄语
保持谦虚好学、术业有专攻、在校的学生,有些知识掌握也比工作好几年掌握的人厉害
第3集 必看-新一代流式计算框架Flink课程相关说明
简介:必看-新一代流式计算框架Flink课程相关准备

学习过程中可能遇到的问题
- 课程有配套的源码,在每章-每集的资料里面,如果没用到代码就不保存。
- 如果自己操作的情况和视频不一样,导入课程代码对比验证基本就可以发现问题了
- 官方要求,务必保持版本一致,不然会遇到很多问题。
- 小滴课堂 - 强调的是学习方式和解决问题的能力,而不是衣来伸手饭来张口,授人以鱼不如授人以渔
- 愿景:"让编程不再难学,让技术与生活更加有趣"
- 小滴课堂-每个技术栈课程不贵,提升自己技术能力 + 不浪费时间 + 涨薪,是超过N倍的收益
记得加我微信+进技术交流群(不管你哪里看到的视频,都可以加我,经常有大厂内推、技术分享等)
![]() 愿景:"让编程不再难学,让技术与生活更加有趣"
愿景:"让编程不再难学,让技术与生活更加有趣"
更多架构课程请访问 xdclass.net
第二章 大数据扫盲贴-大数据领域你必须知道的事情
第1集 零基础扫盲贴-急速认知大数据+人工智能应用领域
简介:零基础扫盲贴-急速认知大数据+机器学习应用领域
前言
- 有相关大数据和机器学习的可以跳过本章
- 主要是给后端、前端、测试 或 零基础学习的同学进行大数据领域的认知
- 当然,如果你想浪费20来分钟,听我掰扯下也行的

什么是大数据?
什么是人工智能
- https://baike.baidu.com/item/%E4%BA%BA%E5%B7%A5%E6%99%BA%E8%83%BD/9180?fr=aladdin
- 人工智能做的不好的,那就是【 人工智障】了
例子(讲很多概念都是虚的,直接上例子大家更容易懂,url过期的话不影响,知道就行)
第2集 零基础扫盲贴 离线计算和实时计算 +流式计算和批量计算你能区分不
简介:零基础扫盲贴-大数据的计算模式的概念
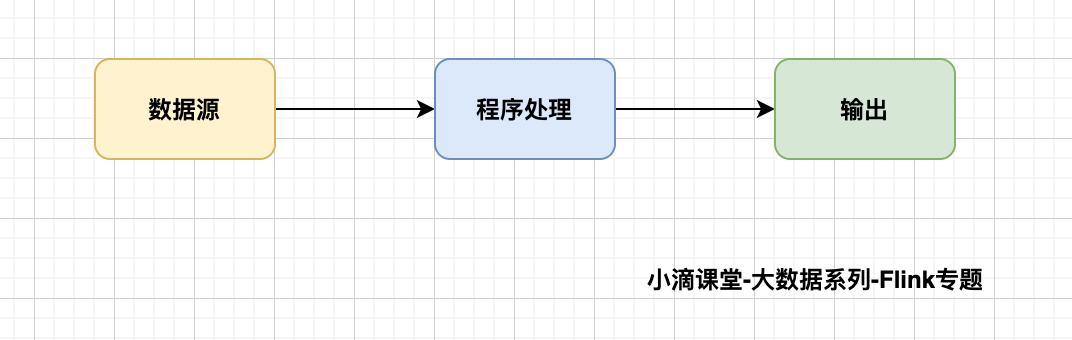
大数据的【计算模式】主要分为两种,适用于不同的大数据应用场景
批量计算(batch computing)
- 批处理:对一定规模量的数据进行处理,类似搬砖,10个10个的搬
- 场景:离线数据统计、报表分析等(过去1年 10000亿条日志,分析日、周、月,接口响应延迟 状态码)
- 特点:批量计算非实时、高延迟,计算完成后才可以得到结果
- 框架:Hadoop MapReduce

流式计算(stream computing)
- 流处理:对源源不断的数据流进行处理,类似水龙头出水
- 特点:流式计算实时、低延迟,实时取最新的结果
- 场景:实时监控、实时风控等
- 框架:Spark(宏观上)、Flink

区分( 离线计算和实时计算 +流式计算和批量计算)
- 离线计算和实时计算 :是对数据处理的【延迟】不一样(一个实时和非实时)
- 流式计算和批量计算: 是对数据处理的【方式】不一样(一个流式和一个批量)
- 结论:离线和批量不等价,实时和流式不等价,因为不是同个维度的东西
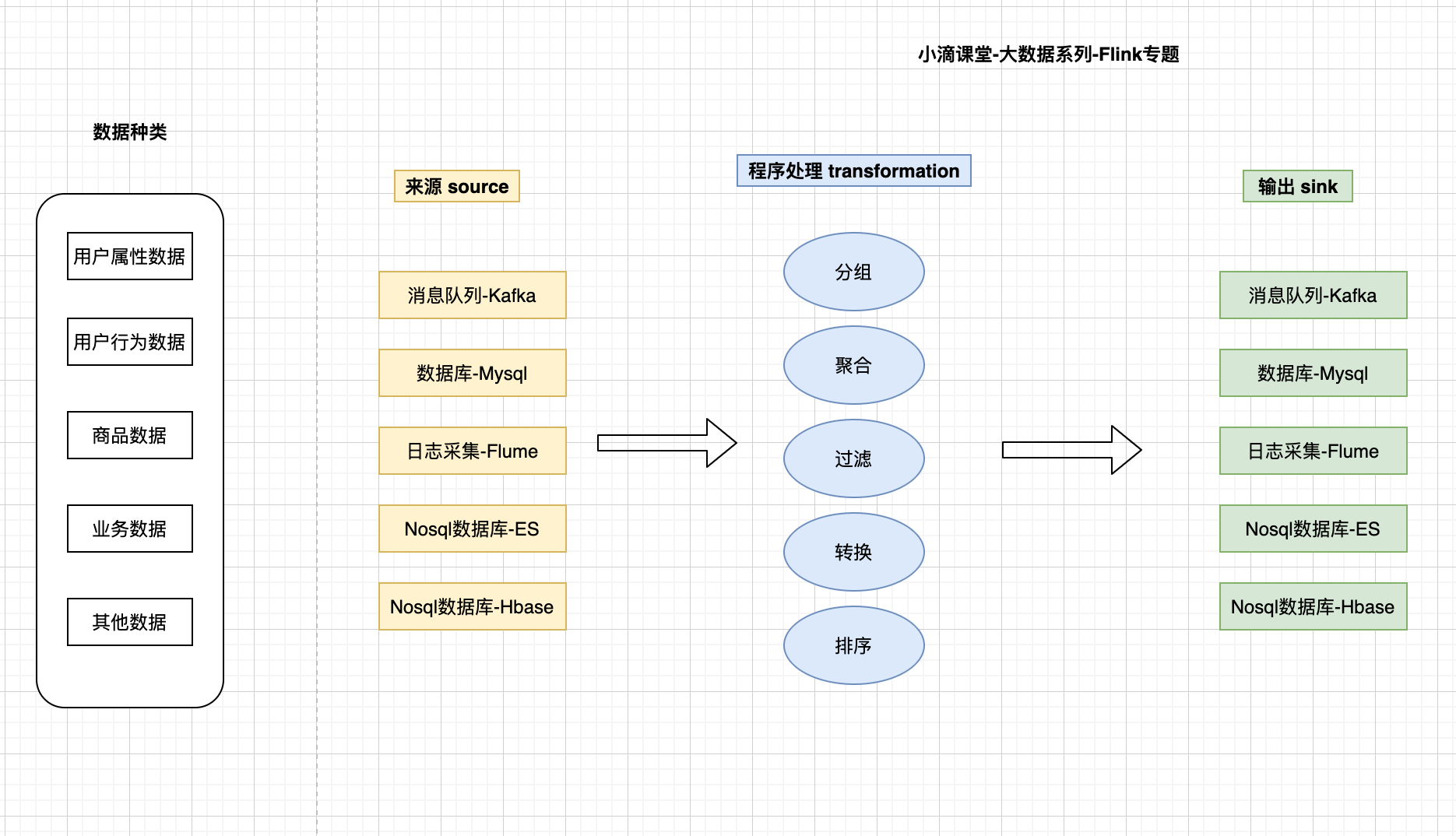
第3集 零基础扫盲贴-大数据里面常用的技术栈和用途
简介:零基础扫盲贴-大数据里面常用的技术栈和用途
- 大数据涉及的技术栈多

大数据技术栈
初级阶段
- Javase+Javaweb
- Idea+maven+git
- Linux+Mysql+Shell
- Springboot+Redis6.X
- Kakfa+Docker
中级阶段
- ELK体系
- Hadoop生态:Hive-Hbase-MapReduce
- Zookeeper
- Flink+Flume
- Scala+Spark
高级阶段
- Zabbix监控+Azkaban任务调度
- Canal+ClickHouse
- Python
- 阿里云ODPS+DataV
- SpringCloud微服务
- 大数据项目实战
- 企业数据中台+DaaS+PaaS
再看下例子(精细化运营)
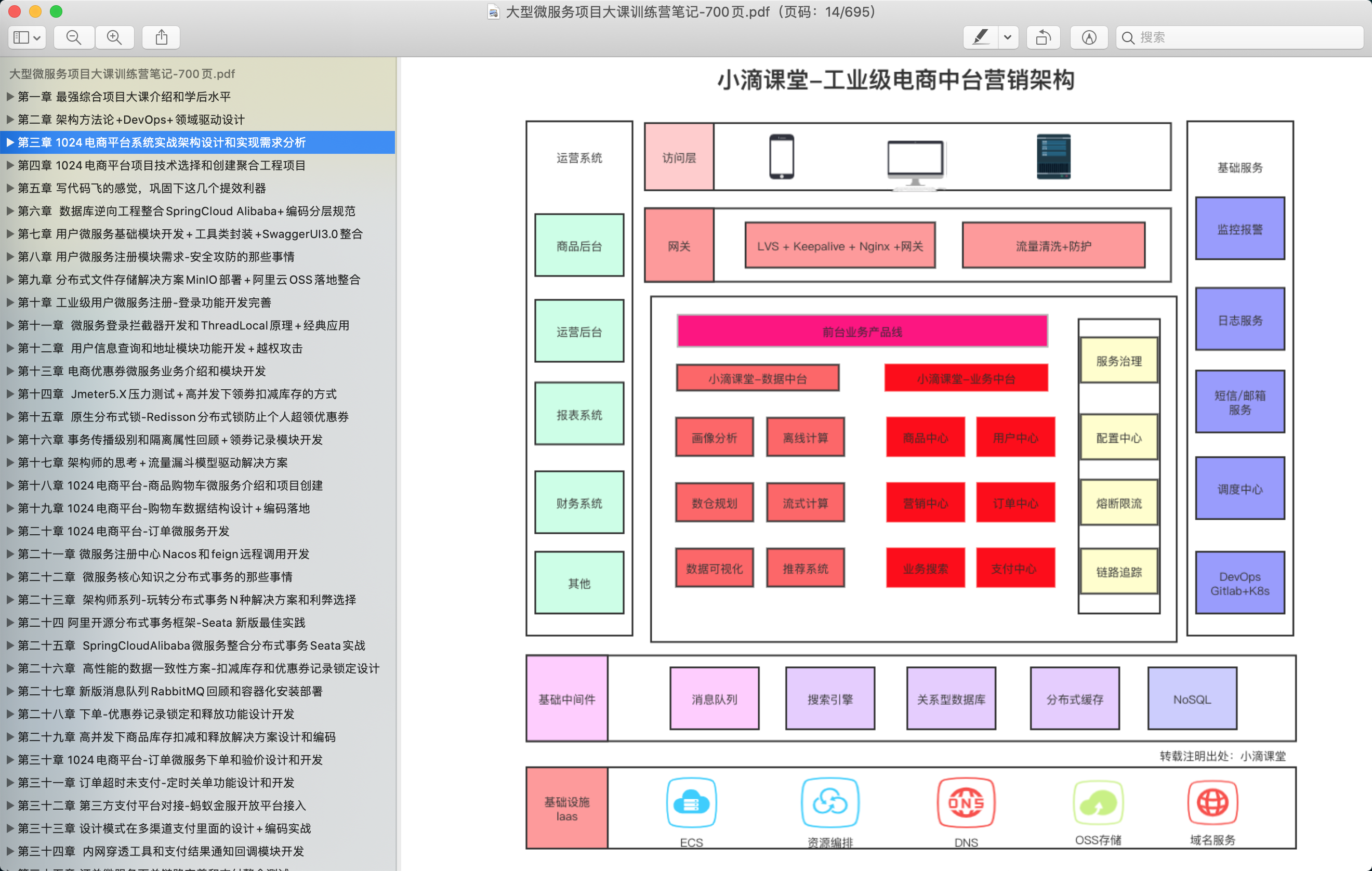
第4集 小滴课堂-大课训练营里面大数据体系的应用
简介:小滴课堂-大课训练营里面大数据体系的应用
- 大课训练营里面的其中一个例子
- 可以加我微信哈(也会不断分享更多例子)
![]() 愿景:"让编程不再难学,让技术与生活更加有趣"
愿景:"让编程不再难学,让技术与生活更加有趣"
更多架构课程请访问 xdclass.net
第三章 新一代流式计算框架Flink急速入门和应用场景
第1集 POJO类的提效利器Lombok插件IDEA安装
简介:讲解lombok的介绍和安装
什么lombok
- 官网:https://projectlombok.org/
- 一个优秀的Java代码库,简化了Java的编码,为Java代码的精简提供了一种方式
你是否发现每个JavaBean都会写getter,setter,equals,hashCode和toString的模板代码,特别的多于没技术
- lombok消除Java的冗长代码,尤其是对于简单的Java对象,只要加上注解就行
使用方式
- 项目添加依赖进行版本管理
<dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><version>1.18.16</version><scope>provided</scope></dependency><!--https://mvnrepository.com/artifact/org.projectlombok/lombok/1.18.16--><!--scope=provided,说明它只在编译阶段生效,不需要打入包中, Lombok在编译期将带Lombok注解的Java文件正确编译为完整的Class文件-->添加IDE工具对Lombok的支持
- 点击File-- Settings设置界面,安装Lombok插件,然后重启idea
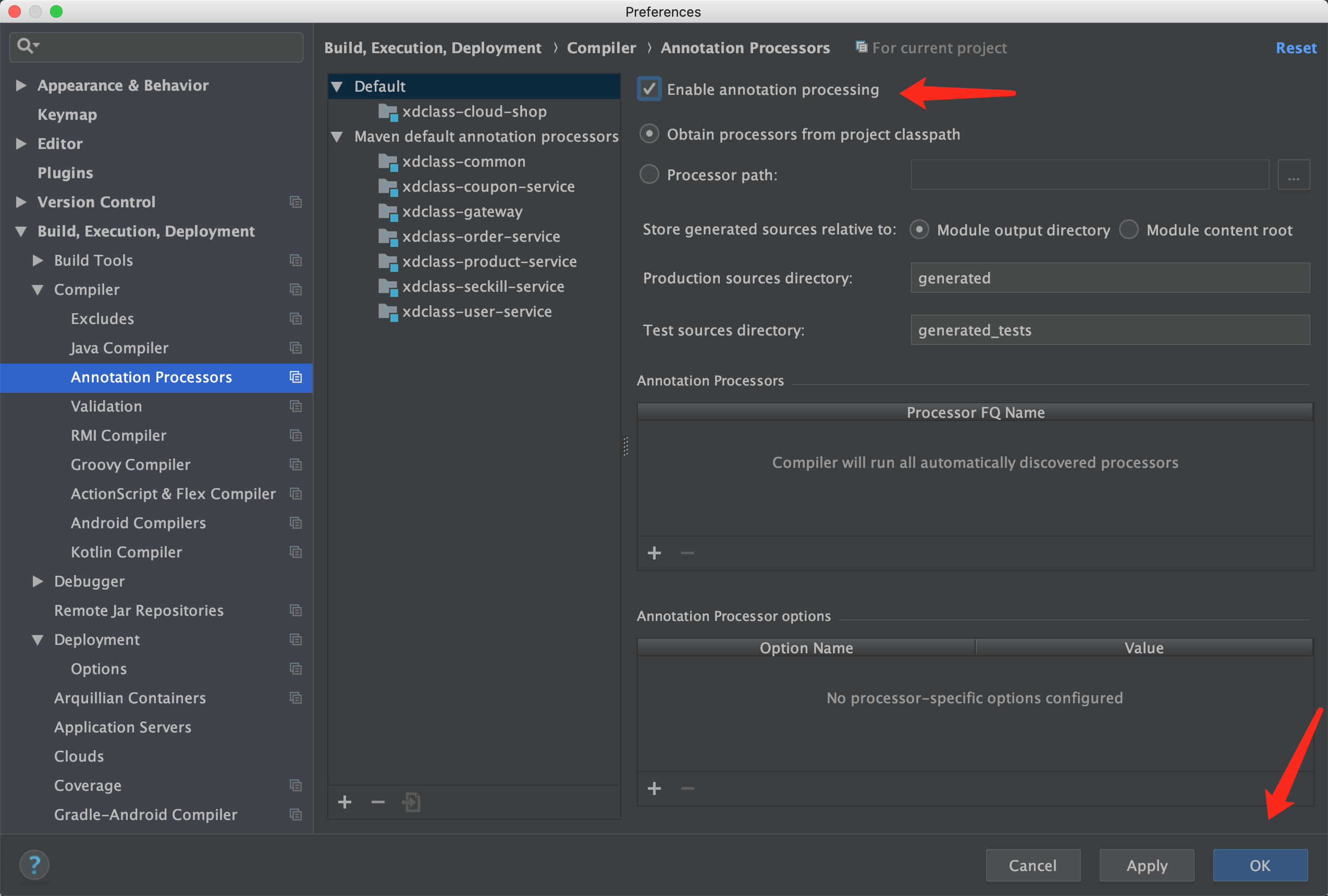
- IDEA里需要在设置中启用annotation processors,记得重启IDEA!!!!
第2集 Flink前奏-完成一个电商订单数据的java需求让你明白用途
简介:Flink前奏-完成一个小的java需求让你明白用途
需求
电商订单数据处理,根据下⾯的list1和list2 各10个订单
- 统计两个⼈的分别购买订单的平均价格
- 统计两个人的订单总价
Lombok插件配置
//总价 35List<VideoOrder> videoOrders1 = Arrays.asList(new VideoOrder("20190242812", "springboot教程", 3),new VideoOrder("20194350812", "微服务SpringCloud", 5),new VideoOrder("20190814232", "Redis教程", 9),new VideoOrder("20190523812", "⽹⻚开发教程", 9),new VideoOrder("201932324", "百万并发实战Netty", 9));//总价 54List<VideoOrder> videoOrders2 = Arrays.asList(new VideoOrder("2019024285312", "springboot教程", 3),new VideoOrder("2019081453232", "Redis教程", 9),new VideoOrder("20190522338312", "⽹⻚开发教程", 9),new VideoOrder("2019435230812", "Jmeter压⼒测试", 5),new VideoOrder("2019323542411", "Git+Jenkins持续集成", 7),new VideoOrder("2019323542424", "Idea全套教程", 21));//订单实体类@Data@AllArgsConstructor@NoArgsConstructorpublic class VideoOrder {private String tradeNo;private String title;private int money;}
- 答案
//两个订单平均价格double videoOrderAvg1 =videoOrders1.stream().collect(Collectors.averagingInt(VideoOrder::getMoney)).doubleValue();System.out.println("订单列表1平均价格="+videoOrderAvg1);double videoOrderAvg2 =videoOrders2.stream().collect(Collectors.averagingInt(VideoOrder::getMoney)).doubleValue();System.out.println("订单列表2平均价格="+videoOrderAvg2);//订单总价int totalMoney1 =videoOrders1.stream().collect(Collectors.summingInt(VideoOrder::getMoney)).intValue();int totalMoney2 =videoOrders2.stream().collect(Collectors.summingInt(VideoOrder::getMoney)).intValue();System.out.println("订单列表1总价="+totalMoney1);System.out.println("订单列表2总价="+totalMoney2);
上面的就是JDK8的Stream流式处理,Flink也是实现类似的功能
- 建议:如果JDK8语法不熟悉,看小滴课堂的jdk8~13新特性语法视频
- 课程地址:https://item.taobao.com/item.htm?id=605926686253
第3集 JDK8 里面的Stream和流式处理框架Flink对比
简介:JDK8 里面的Stream和流式处理框架Flink对比
上集完成了一个需求,工作里面应用也是类似的流程链路
- 为啥java程序本身可以做的,还要学Flink?
- 想实现当下企业用一个Flink的需求,你不用Flink也行的
- 要是你开心可以用纯java代码、或者spark其他框架

JDK8 Stream也是流处理,flink也是流处理, 那区别点来啦
数据来源和输出有多样化怎么处理;
- jdk stream -写代码
- flink - 自带很多组件
海量数据需要进行实时处理
- jdk stream - 内部jvm单节点处理,单机内部并行处理
- flink - 节点可以分布在不同机器的JVM上,多机器并行处理
统计时间段内数据,但数据达到是无序的
- jdk stream -写代码
- flink - 自带窗口函数和watermark处理迟到数据
其他太多。。。。
为了实现一个天猫双十一实时交易大盘各个品类数据展示功能
小滴课堂-老王说他乐意这样写java代码,你奈我何??
- 一个功能耗时1个月完成,需求不敢轻易改动
二当家小D采用了Flink进行开发这个功能
- 1周搞定,需求可以灵活变动

大型互联网公司都有的数据监控后台例子
- 阿里、腾讯自研
- 神策数据、百度统计
第4集 新一代流式处理框架Flink介绍和重要概念讲解
简介:新一代流式处理框架Flink介绍和重要概念讲解
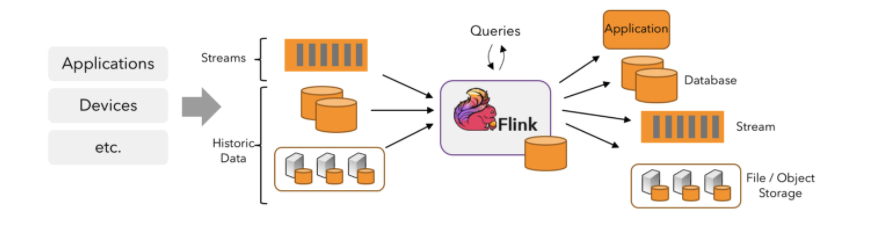
什么是Flink
Apache Flink 是一个框架和分布式处理引擎,用于在无边界和有边界数据流上进行有状态的计算
官网:https://flink.apache.org/zh/flink-architecture.html
有谁在用呢(基本大厂都在用)
- 用来做啥:实时数仓建设、实时数据监控、实时反作弊风控、画像系统等


概念
数据流
- 任何类型的数据都可以形成一种事件流,信用卡交易、传感器测量、机器日志、网站或移动应用程序上的用户交互记录,所有这些数据都形成一种流。
什么是有界流
- 有定义流的开始,也有定义流的结束。有界流可以在摄取所有数据后再进行计算。有界流所有数据可以被排序,所以并不需要有序摄取。有界流处理通常被称为批处理
什么是无界流
- 有定义流的开始,但没有定义流的结束。它们会无休止地产生数据。无界流的数据必须持续处理,即数据被摄取后需要立刻处理。我们不能等到所有数据都到达再处理,因为输入是无限的,在任何时候输入都不会完成。处理无界数据通常要求以特定顺序摄取事件,例如事件发生的顺序,以便能够推断结果的完整性。
Apache Flink 擅长处理无界和有界数据集,有出色的性能
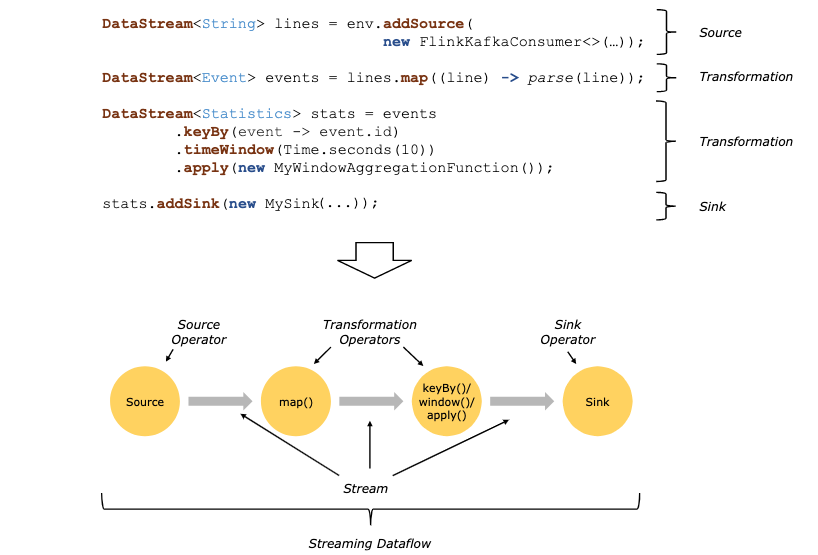
代码使用例子
- source、transformation、sink 都是 operator算子
![]() 愿景:"让编程不再难学,让技术与生活更加有趣"
愿景:"让编程不再难学,让技术与生活更加有趣"
更多架构课程请访问 xdclass.net
第四章 夜深人静的时候 完成第一个Flink 流批一体案例
第1集 带你飞速体验第一个Flink案例-java版本环境搭建
简介:带你飞速体验第一个Flink案例-java版本环境搭建
创建项目
- maven项目
- jdk8或11
添加依赖(后续有变动再调整)
<properties><encoding>UTF-8</encoding><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding><maven.compiler.source>1.8</maven.compiler.source><maven.compiler.target>1.8</maven.compiler.target><java.version>1.8</java.version><scala.version>2.12</scala.version><flink.version>1.13.1</flink.version></properties><dependencies><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><version>1.18.16</version></dependency><!--flink客户端--><dependency><groupId>org.apache.flink</groupId><artifactId>flink-clients_${scala.version}</artifactId><version>${flink.version}</version></dependency><!--scala版本--><dependency><groupId>org.apache.flink</groupId><artifactId>flink-scala_${scala.version}</artifactId><version>${flink.version}</version></dependency><!--java版本--><dependency><groupId>org.apache.flink</groupId><artifactId>flink-java</artifactId><version>${flink.version}</version></dependency><!--streaming的scala版本--><dependency><groupId>org.apache.flink</groupId><artifactId>flink-streaming-scala_${scala.version}</artifactId><version>${flink.version}</version></dependency><!--streaming的java版本--><dependency><groupId>org.apache.flink</groupId><artifactId>flink-streaming-java_${scala.version}</artifactId><version>${flink.version}</version></dependency><!--日志输出--><dependency><groupId>org.slf4j</groupId><artifactId>slf4j-log4j12</artifactId><version>1.7.7</version><scope>runtime</scope></dependency><dependency><groupId>log4j</groupId><artifactId>log4j</artifactId><version>1.2.17</version><scope>runtime</scope></dependency><!--json依赖包--><dependency><groupId>com.alibaba</groupId><artifactId>fastjson</artifactId><version>1.2.44</version></dependency></dependencies>
- 日志配置 log4j.properties
### 配置appender名称log4j.rootLogger = debugFile, errorFile### debug级别以上的日志到:src/logs/debug.loglog4j.appender.debugFile = org.apache.log4j.DailyRollingFileAppenderlog4j.appender.debugFile.File = src/logs/flink.loglog4j.appender.debugFile.Append = true#Threshold属性指定输出等级log4j.appender.debugFile.Threshold = infolog4j.appender.debugFile.layout = org.apache.log4j.PatternLayoutlog4j.appender.debugFile.layout.ConversionPattern = %-d{yyyy-MM-dd HH:mm:ss} [ %t:%r ] - [ %p ] %n%m%n### error级别以上的日志 src/logs/error.loglog4j.appender.errorFile = org.apache.log4j.DailyRollingFileAppenderlog4j.appender.errorFile.File = src/logs/error.loglog4j.appender.errorFile.Append = truelog4j.appender.errorFile.Threshold = errorlog4j.appender.errorFile.layout = org.apache.log4j.PatternLayoutlog4j.appender.errorFile.layout.ConversionPattern = %-d{yyyy-MM-dd HH:mm:ss} [ %t:%r ] - [ %p ] %n%m%n
第2集 Tuple元组数据类型 + Map + FlatMap操作介绍
简介:Tuple数据类型+Map+FlatMap操作介绍
什么是Tuple类型
元组类型, 多个语言都有的特性, flink的java版 tuple最多支持25个
用途
- 函数返回(return)多个值,多个不同类型的对象
- List集合不是也可以吗,集合里面是单个类型
- 列表只能存储相同的数据类型,而元组Tuple可以存储不同的数据类型
Tuple3<Integer, String, Double> t = Tuple3.of(1,"xdclass.net",32.1);System.out.println(t.f0);System.out.println(t.f1);System.out.println(t.f2);
什么是java里面的Map操作
- 一对一 转换对象,比如DO转DTO
什么是java里面的FlatMap操作
- 一对多转换对象
List<String> list1 = new ArrayList<>();list1.add("springboot,springcloud");list1.add("redis6,docker");list1.add("kafka,rabbitmq");//一对一转换List<String> list2 = list1.stream().map(obj -> {obj = "小滴课堂" + obj;return obj;}).collect(Collectors.toList());System.out.println(list2);//一对多转换List<String> list3 = list1.stream().flatMap(obj -> {return Arrays.stream(obj.split(","));}).collect(Collectors.toList());System.out.println(list3);
第3集 带你飞速体验第一个Flink 流处理案例-代码编写实战
简介:带你飞速体验第一个Flink案例-代码编写实战
需求
- 根据字符串的逗号进行分割,输出
- 大家学起来的疑惑点:生产环境是不是也是这样main函数写???
代码
xxxxxxxxxxpublic static void main(String[] args) throws Exception {//构建执行任务环境以及任务的启动的入口, 存储全局相关的参数StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();//相同类型元素的数据流DataStream<String> stringDataStream = env.fromElements("java,springboot","java,springcloud");// FlatMapFunction<String, String>, key是输入类型,value是Collector响应的收集的类型,看源码注释,也是 DataStream<String>里面泛型类型DataStream<String> flatMapDataStream = stringDataStream.flatMap(new FlatMapFunction<String, String>() {@Overridepublic void flatMap(String value, Collector<String> out) throws Exception {String[] arr = value.split(",");for (String word : arr) {out.collect(word);}}});flatMapDataStream.print("结果");//DataStream需要调用execute,可以取个名称env.execute("data stream job");}
第4集 带你飞速体验第一个Flink 批处理案例-代码编写实战
简介:带你飞速体验第一个Flink案例-代码编写实战
需求
- 根据字符串的逗号进行分割,输出
代码
xxxxxxxxxxpublic static void main(String [] args) throws Exception {//构建执行任务环境以及任务的启动的入口, 存储全局相关的参数ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();//设置并行度env.setParallelism(1);//相同类型元素的数据集 sourceDataSet<String> stringDS = env.fromElements("java,SpringBoot", "spring cloud,redis", "kafka,小滴课堂");stringDS.print("处理前");// FlatMapFunction<String, String>, key是输入类型,value是Collector响应的收集的类型,看源码注释,也是 DataStream<String>里面泛型类型DataSet<String> flatMapDS = stringDS.flatMap(new FlatMapFunction<String, String>() {@Overridepublic void flatMap(String value, Collector<String> collector) throws Exception {String [] arr = value.split(",");for(String str : arr){collector.collect(str);}}});//输出 sinkflatMapDS.print("处理后");//DataStream需要调用execute,可以取个名称env.execute("flat map job");}处理前> java,SpringBoot处理前> spring cloud,redis处理前> kafka,小滴课堂处理后> java处理后> SpringBoot处理后> spring cloud处理后> redis处理后> kafka处理后> 小滴课堂
注意
- Flink1.12时支持流批一体,DataSetAPI已经不推荐使用了,案例都会优先使用DataStream流式API
第5集 你的疑惑-Blink介绍和IDEA里面运行Flink运行流程解析
简介:Blink介绍和IDEA里面运行Flink运行流程解析
Flink和Blink关系
2019年Flink的母公司被阿里全资收购
阿里进行高度定制并取名为Blink (加了很多特性 )
阿里巴巴官方说明:Blink不会单独作为一个开源项目运作,而是Flink的一部分
都在不断演进中,对比其他流式计算框架(老到新)
- Storm 只支持流处理
- Spark Streaming (流式处理,其实是micro-batch微批处理,本质还是批处理)
- Flink 支持流批一体
算子Operator
- 将一个或多个DataStream转换为新的DataStream,可以将多个转换组合成复杂的数据流拓扑
- Source 和 Sink 是数据输入和数据输出的特殊算子,重点是transformation类的算子
- 代码
xxxxxxxxxxStreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
那我们在IDEA里面运行这样就行?实际项目也是这样用???
- flink可以本地idea执行模拟多线程执行,但不能读取配置文件,适合本地调试
- 可以提交到远程搭建的flink集群
- getExecutionEnvironment() 是flink封装好的方式可以自动判断运行模式,更方便开发,
- 如果程序是独立调用的,此方法返回本地执行环境;
- 如果从命令行客户端调用程序以提交到集群,则返回此集群的执行环境,是最常用的一种创建执行环境的方式
最终线上部署会把main函数打成jar包,提交到Flink进群进行运行, 会有UI可视化界面
服务端部署例子(后续会讲)
Flink 部署方式是灵活,主要是对Flink计算时所需资源的管理方式不同
- Local 本地部署,直接启动进程,适合调试使用
- Standalone Cluster集群部署,flink自带集群模式
- On Yarn 计算资源统一由Hadoop YARN管理资源进行调度,按需使用提高集群的资源利用率,生产环境
第6集 Flink可视化控制台依赖配置和界面介绍
简介:Flink可视化控制台依赖配置和界面介绍
WebUI可视化界面
- 访问:ip:8081
- 方式一:服务端部署Flink集群(生产环境)
- 方式二:本地依赖添加(测试开发)
xxxxxxxxxx<!--Flink web ui--><dependency><groupId>org.apache.flink</groupId><artifactId>flink-runtime-web_${scala.version}</artifactId><version>${flink.version}</version></dependency>代码开发
xxxxxxxxxxpublic static void main(String[] args) throws Exception {final StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(new Configuration());//env.setParallelism(1);DataStream<String> stringDataStream = env.socketTextStream("127.0.0.1",8888);DataStream<String> flatMapDataStream = stringDataStream.flatMap(new FlatMapFunction<String, String>() {@Overridepublic void flatMap(String value, Collector<String> out) throws Exception {String[] arr = value.split(",");for (String word : arr) {out.collect(word);}}});flatMapDataStream.print("结果");//DataStream需要调用execute,可以取个名称env.execute("data stream job");}nc命令介绍
- Linux nc命令用于设置网络路由的
- nc -lk 8888
- 开启 监听模式,用于指定nc将处于监听模式, 等待客户端来链接指定的端口
win | linux 需要安装
win 百度搜索博文参考不同系统安装
linux 安装
- yum install -y netcat
- yum install -y nc
![]() 愿景:"让编程不再难学,让技术与生活更加有趣"
愿景:"让编程不再难学,让技术与生活更加有趣"
更多架构课程请访问 xdclass.net
第五章【高级篇】流式计算框架Flink 部署和整体架构讲解
第1集 Flink常见的运行部署模式介绍和运行流程浅析
简介:Flink常见的运行部署模式介绍和运行流程浅析
建议:第一遍看大概,等学完整个后看第二遍
Flink 部署方式是灵活,主要是对Flink计算时所需资源的管理方式不同
- Local 本地部署,直接启动进程,适合调试使用
- Standalone Cluster集群部署,flink自带集群模式
- On Yarn 计算资源统一由Hadoop YARN管理资源进行调度,按需使用提高集群的资源利用率,生产环境
运行流程
用户提交Flink程序到JobClient,
JobClient的 解析、优化提交到JobManager
TaskManager运行task, 并上报信息给JobManager
通俗解释
- JobManager 包工头
- TaskManager 任务组长
- Task solt 工人 (并行去做事情)

第2集 深入Flink整体架构原理和组件角色介绍《上》
简介:Flink整体架构和组件角色介绍
- 建议:第一遍看大概,等学完整个后看第二遍
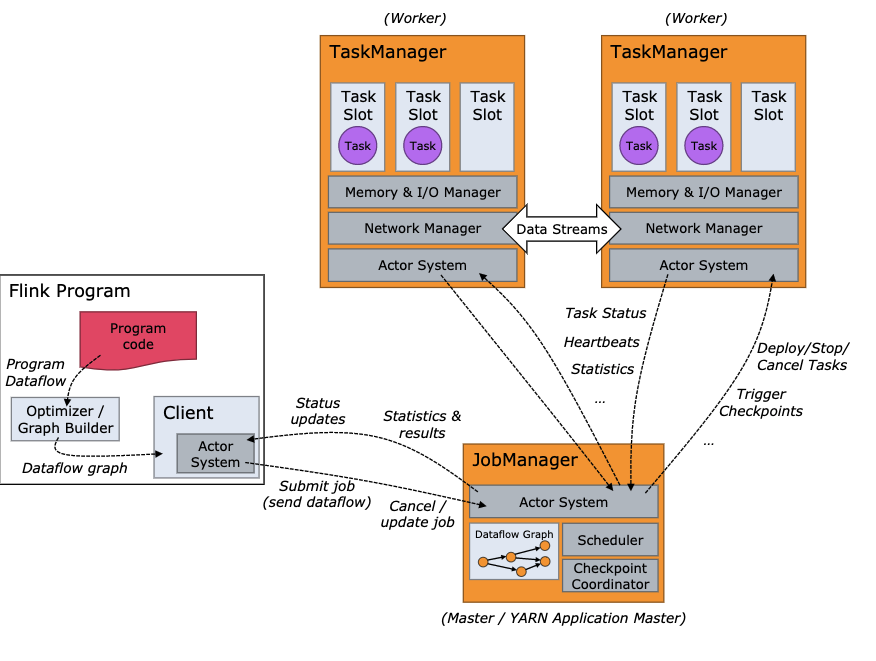
Flink 是一个分布式系统,需要有效分配和管理计算资源才能执行流应用程序
运行时由两种类型的进程组成
- 一个 JobManager
- 一个或者多个 TaskManager。
什么是JobManager(大Boss,包工头)
协调 Flink 应用程序的分布式执行的功能
- 它决定何时调度下一个 task(或一组 task)
- 对完成的 task 或执行失败做出反应
- 协调 checkpoint、并且协调从失败中恢复等等
什么是TaskManager (任务组长,搬砖的人)
- 负责计算的worker,还有上报内存、任务运行情况给JobManager等
- 至少有一个 TaskManager,也称为 worker执行作业流的 task,并且缓存和交换数据流
- 在 TaskManager 中资源调度的最小单位是 task slot
第3集 深入Flink整体架构原理和组件角色介绍《中》
简介:Flink整体架构和组件角色介绍
建议:第一遍看大概,等学完整个后看第二遍
Jobmanager进阶
JobManager进程由三个不同的组件组成
ResourceManager
- 负责 Flink 集群中的资源提供、回收、分配 - 它管理 task slots
Dispatcher
- 提供了一个 REST 接口,用来提交 Flink 应用程序执行
- 为每个提交的作业启动一个新的 JobMaster。
- 运行 Flink WebUI 用来提供作业执行信息
JobMaster
- 负责管理单个JobGraph的执行,Flink 集群中可以同时运行多个作业,每个作业都有自己的 JobMaster
- 至少有一个 JobManager,高可用(HA)设置中可能有多个 JobManager,其中一个始终是 leader,其他的则是 standby
TaskManager 进阶
TaskManager中 task slot 的数量表示并发处理 task 的数量
一个 task slot 中可以执行多个算子,里面多个线程
算子 opetator
- source
- transformation
- sink
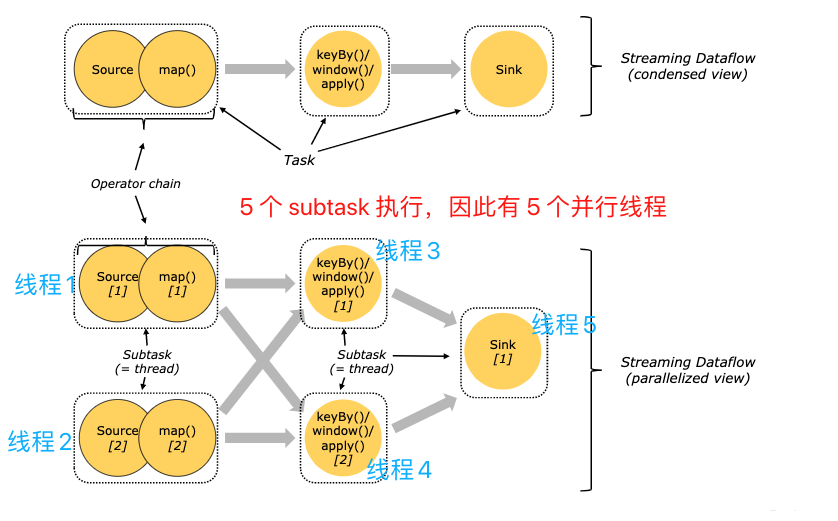
对于分布式执行,Flink 将算子的 subtasks 链接成 tasks,每个 task 由一个线程执行
- 图中source和map算子组成一个算子链,作为一个task运行在一个线程上
将算子链接成 task 是个有用的优化:它减少线程间切换、缓冲的开销,并且减少延迟的同时增加整体吞吐量
第4集 深入Flink整体架构原理和组件角色介绍《下》
简介:Flink整体架构和组件角色介绍
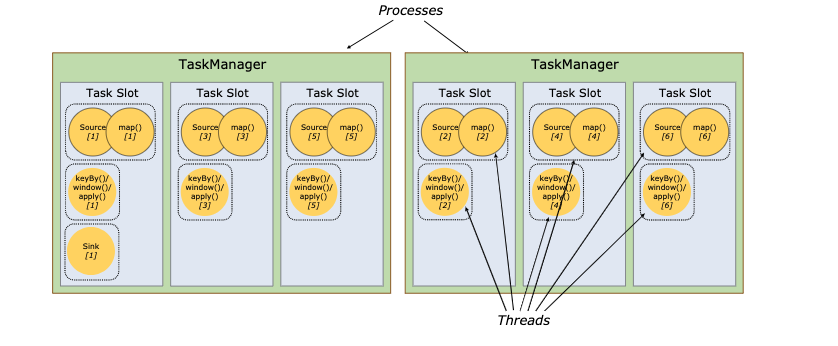
Task Slots 任务槽
Task Slot是Flink中的任务执行器,每个Task Slot可以运行多个subtask ,每个subtask会以单独的线程来运行
每个 worker(TaskManager)是一个 JVM 进程,可以在单独的线程中执行一个(1个solt)或多个 subtask
为了控制一个 TaskManager 中接受多少个 task,就有了所谓的 task slots(至少一个)
每个 task slot 代表 TaskManager 中资源的固定子集
注意
- 所有Task Slot平均分配TaskManger的内存, TaskSolt 没有 CPU 隔离
- 当前 TaskSolt 独占内存空间,作业间互不影响
- 一个TaskManager进程里有多少个taskSolt就意味着多少个并发
- task solt数量建议是cpu的核数,独占内存,共享CPU
5 个 subtask 执行,因此有 5 个并行线程
Task 正好封装了一个 Operator 或者 Operator Chain 的 parallel instance。
Sub-Task 强调的是同一个 Operator 或者 Operator Chain 具有多个并行的 Task
图中source和map算子组成一个算子链,作为一个task运行在一个线程上
- 算子链接成 一个 task 它减少线程间切换、缓冲的开销,并且减少延迟的同时增加整体吞吐量
- Task Slot是Flink中的任务执行器,每个Task Slot可以运行多个task即subtask ,每个sub task会以单独的线程来运行
- Flink 算子之间可以通过【一对一】模式或【重新分发】模式传输数据
文档
第5集 Flink的并行度概念理解和调整优先级说明
简介:Flink的并行度概念理解和调整优先级说明
Flink 是分布式流式计算框架
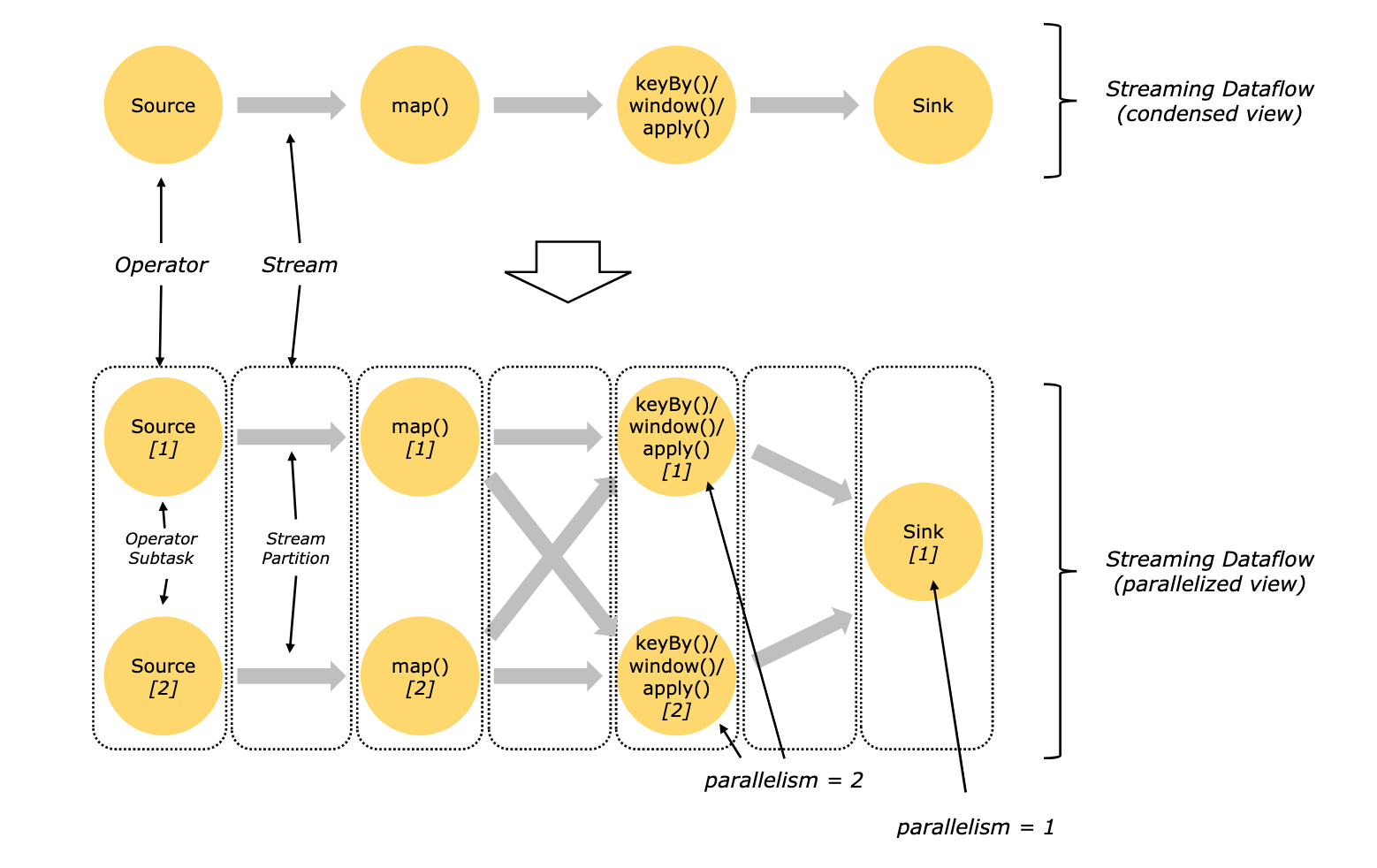
- 程序在多节点并行执行,所以就有并行度 Parallelism
- DataStream 就像是有向无环图(DAG),每一个 数据流(DataStream) 以一个或多个 source 开始,以一个或多个 sink 结束
流程
- 一个数据流( stream) 包含一个或多个分区,在不同的线程/物理机里并行执行
- 每一个算子( operator) 包含一个或多个子任务( subtask),子任务在不同的线程/物理机里并行执行
- 一个算子的子任务subtask 的个数就是并行度( parallelism)
并行度的调整配置
Flink流程序中不同的算子可能具有不同的并行度,可以在多个地方配置,有不同的优先级
Flink并行度配置级别 (高到低)
算子
- map( xxx ).setParallelism(2)
全局env
- env.setParallelism(2)
客户端cli
- ./bin/flink run -p 2 xxx.jar
Flink配置文件
- /conf/flink-conf.yaml 的 parallelism.defaul 默认值
某些算子无法设置并行度
本地IDEA运行 并行度默认为cpu核数
一个很重要的区分 TaskSolt和parallelism并行度配置
- task slot是静态的概念,是指taskmanager具有的并发执行能力;
- parallelism是动态的概念,是指 程序运行时实际使用的并发能力
- 前者是具有的能力比如可以100个,后者是实际使用的并发,比如只要20个并发就行。

Flink有3中运行模式
xxxxxxxxxxenv.setRuntimeMode(RuntimeExecutionMode.STREAMING);- STREAMING 流处理
- BATCH 批处理
- AUTOMATIC 根据source类型自动选择运行模式,基本就是使用这个
![]() 愿景:"让编程不再难学,让技术与生活更加有趣"
愿景:"让编程不再难学,让技术与生活更加有趣"
更多架构课程请访问 xdclass.net
第六章 玩转Flink里面核心的Source Operator实战
第1集 Flink 的API层级介绍Source Operator速览
简介:Flink 的API层级介绍Source Operator速览
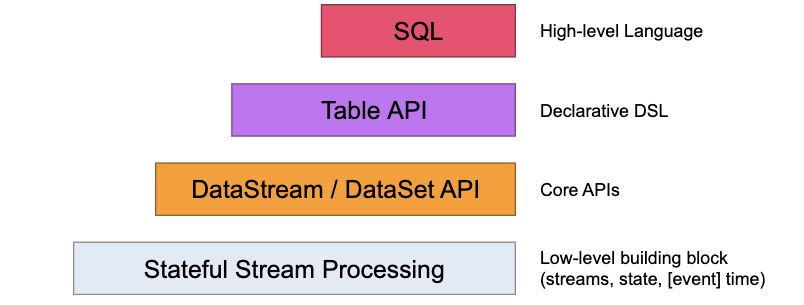
Flink的API层级 为流式/批式处理应用程序的开发提供了不同级别的抽象
第一层是最底层的抽象为有状态实时流处理,抽象实现是 Process Function,用于底层处理
第二层抽象是 Core APIs,许多应用程序不需要使用到上述最底层抽象的 API,而是使用 Core APIs 进行开发
- 例如各种形式的用户自定义转换(transformations)、联接(joins)、聚合(aggregations)、窗口(windows)和状态(state)操作等,此层 API 中处理的数据类型在每种编程语言中都有其对应的类。
第三层抽象是 Table API。 是以表Table为中心的声明式编程API,Table API 使用起来很简洁但是表达能力差
- 类似数据库中关系模型中的操作,比如 select、project、join、group-by 和 aggregate 等
- 允许用户在编写应用程序时将 Table API 与 DataStream/DataSet API 混合使用
第四层最顶层抽象是 SQL,这层程序表达式上都类似于 Table API,但是其程序实现都是 SQL 查询表达式
- SQL 抽象与 Table API 抽象之间的关联是非常紧密的
注意:Table和SQL层变动多,还在持续发展中,大致知道即可,核心是第一和第二层
- Flink编程模型
Source来源
元素集合
- env.fromElements
- env.fromColletion
- env.fromSequence(start,end);
文件/文件系统
- env.readTextFile(本地文件);
- env.readTextFile(HDFS文件);
基于Socket
- env.socketTextStream("ip", 8888)
自定义Source,实现接口自定义数据源,rich相关的api更丰富
并行度为1
- SourceFunction
- RichSourceFunction
并行度大于1
- ParallelSourceFunction
- RichParallelSourceFunction
Connectors与第三方系统进行对接(用于source或者sink都可以)
- Flink本身提供Connector例如kafka、RabbitMQ、ES等
- 注意:Flink程序打包一定要将相应的connetor相关类打包进去,不然就会失败
Apache Bahir连接器
- 里面也有kafka、RabbitMQ、ES的连接器更多
总结 和外部系统进行读取写入的
第一种 Flink 里面预定义的 source 和 sink。
第二种 Flink 内部也提供部分 Boundled connectors。
第三种是第三方 Apache Bahir 项目中的连接器。
第四种是通过异步 IO 方式
- 异步I/O是Flink提供的非常底层的与外部系统交互
第2集 Flink 预定义的Source 数据源 案例实战《上》
简介:预定义的Source 数据源 案例实战
Source来源
元素集合
- env.fromElements
- env.fromColletion
- env.fromSequence(start,end);
xxxxxxxxxxpublic static void main(String [] args) throws Exception {//构建执行任务环境以及任务的启动的入口, 存储全局相关的参数StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();//相同类型元素的数据流 sourceDataStream<String> stringDS1 = env.fromElements("java,SpringBoot", "spring cloud,redis", "kafka,小滴课堂");stringDS1.print("stringDS1");DataStream<String> stringDS2 = env.fromCollection(Arrays.asList("微服务项目大课,java","alibabacloud,rabbitmq","hadoop,hbase"));stringDS2.print("stringDS2");DataStreamSource<Long> longDS3 = env.fromSequence(0,10);longDS3.print("longDS3");//DataStream需要调用execute,可以取个名称env.execute("xdclass job");}
第3集 Flink 预定义的Source 数据源案例实战《下》
简介:预定义的Source 数据源案例实战
文件/文件系统
- env.readTextFile(本地文件);
- env.readTextFile(HDFS文件);
xxxxxxxxxxpublic static void main(String [] args) throws Exception {//构建执行任务环境以及任务的启动的入口, 存储全局相关的参数StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);DataStream<String> textDS = env.readTextFile("/Users/xdclass/Desktop/xdclass_access.log");//DataStream<String> textDS = env.readTextFile("hdfs://xdclass_node:8010/file/log/words.txt");textDS.print();env.execute("xdclass job");}
基于Socket
- env.socketTextStream("ip", 8888)
xxxxxxxxxxpublic static void main(String [] args) throws Exception {//构建执行任务环境以及任务的启动的入口, 存储全局相关的参数StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);DataStream<String> stringDataStream = env.socketTextStream("127.0.0.1",8888);stringDataStream.print();env.execute("xdclass job");}
第4集 Flink自定义的Source 数据源案例-订单来源实战
简介: Flink自定义的Source 数据源案例-订单来源实战
自定义Source,实现接口自定义数据源
并行度为1
- SourceFunction
- RichSourceFunction
并行度大于1
- ParallelSourceFunction
- RichParallelSourceFunction
Rich相关的api更丰富,多了Open、Close方法,用于初始化连接等
创建接口
xxxxxxxxxx@Data@AllArgsConstructor@NoArgsConstructorpublic class VideoOrder {private String tradeNo;private String title;private int money;private int userId;private Date createTime;}public class VideoOrderSource extends RichParallelSourceFunction<VideoOrder> {private volatile Boolean flag = true;private Random random = new Random();private static List<String> list = new ArrayList<>();static {list.add("spring boot2.x课程");list.add("微服务SpringCloud课程");list.add("RabbitMQ消息队列");list.add("Kafka课程");list.add("小滴课堂面试专题第一季");list.add("Flink流式技术课程");list.add("工业级微服务项目大课训练营");list.add("Linux课程");}@Overridepublic void run(SourceContext<VideoOrder> ctx) throws Exception {while (flag){Thread.sleep(1000);String id = UUID.randomUUID().toString();int userId = random.nextInt(10);int money = random.nextInt(100);int videoNum = random.nextInt(list.size());String title = list.get(videoNum);ctx.collect(new VideoOrder(id,title,money,userId,new Date()));}}/*** 取消任务*/@Overridepublic void cancel() {flag = false;}}
- 案例
xxxxxxxxxxpublic static void main(String [] args) throws Exception {//构建执行任务环境以及任务的启动的入口, 存储全局相关的参数StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();DataStream<VideoOrder> videoOrderDataStream = env.addSource(new VideoOrderSource());videoOrderDataStream.print();//DataStream需要调用execute,可以取个名称env.execute("custom source job");}
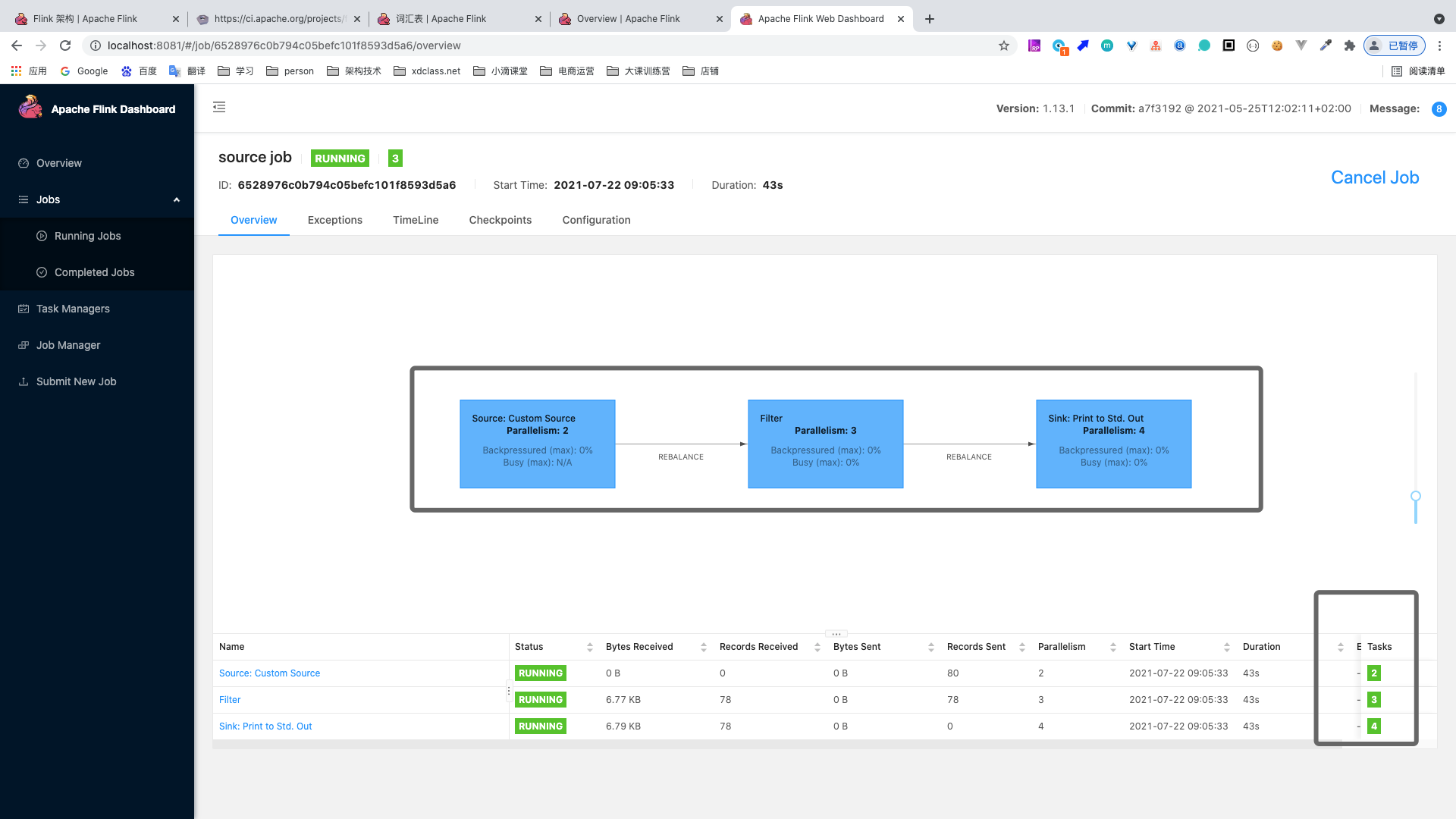
第5集 Flink自定义的Source 数据源案例-并行度调整结合WebUI
简介: Flink自定义的Source 数据源案例-并行度调整结合WebUI
- 开启webui
xxxxxxxxxxStreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(new Configuration());
- 设置不同的并行度
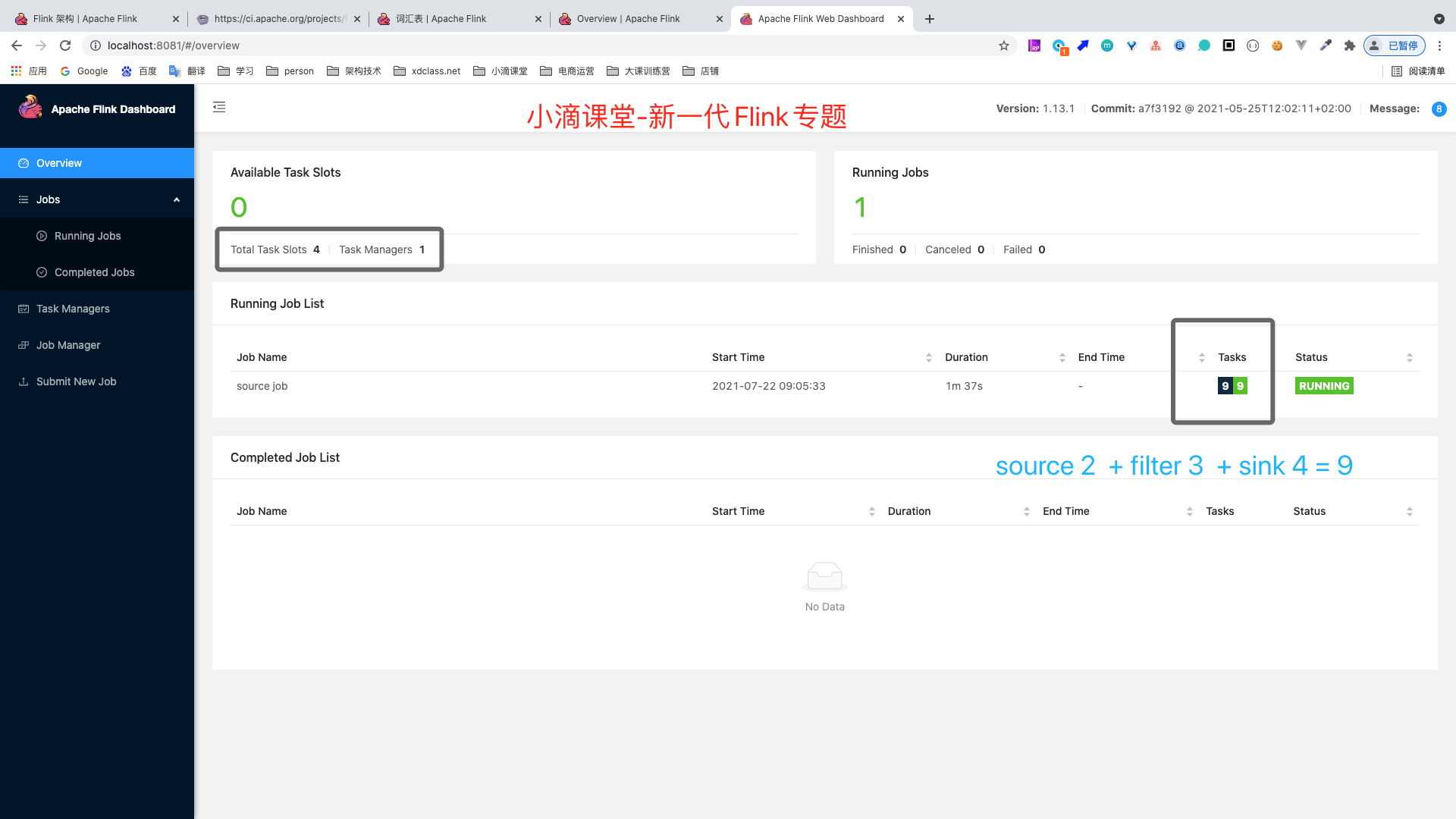
xxxxxxxxxxpublic static void main(String[] args) throws Exception {//构建执行任务环境以及任务的启动的入口, 存储全局相关的参数//StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(new Configuration());env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);env.setParallelism(2);DataStream<VideoOrder> videoOrderDS = env.addSource(new VideoOrderSource());DataStream<VideoOrder> filterDS = videoOrderDS.filter(new FilterFunction<VideoOrder>() {@Overridepublic boolean filter(VideoOrder videoOrder) throws Exception {return videoOrder.getMoney()>5;}}).setParallelism(3);filterDS.print().setParallelism(4);//DataStream需要调用execute,可以取个名称env.execute("source job");}
- 数据流中最大的并行度,就是算子链中最大算子的数量,比如source 2个并行度,filter 4个,sink 4个,最大就是4
![]() 愿景:"让编程不再难学,让技术与生活更加有趣"
愿景:"让编程不再难学,让技术与生活更加有趣"
更多架构课程请访问 xdclass.net
第七章 玩转Flink里面核心的Sink Operator实战
第1集 Flink 核心知识 Sink Operator速览
简介:Flink 的核心知识 Sink Operator
- Flink编程模型
Sink 输出源
预定义
- writeAsText (过期)
自定义
SinkFunction
RichSinkFunction
- Rich相关的api更丰富,多了Open、Close方法,用于初始化连接等
flink官方提供 Bundle Connector
- kafka、ES 等
Apache Bahir
- kafka、ES、Redis等
- 预定义Sink输出实战
第2集 Flink 自定义的Sink 连接Mysql存储商品订单案例实战《上》
简介:Flink 自定义的SinkFunction 数据源输出案例实战
自定义
SinkFunction
RichSinkFunction
- Rich相关的api更丰富,多了Open、Close方法,用于初始化连接等
Flink连接mysql的几种方式(都需要加jdbc驱动)
- 方式一:自带flink-connector-jdbc 需要加依赖包
xxxxxxxxxx<dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-jdbc_2.12</artifactId><version>1.12.0</version></dependency>- 方式二:自定义sink
保存视频订单到Mysql
Mysql环境自己本地搭建
建表
xxxxxxxxxxCREATE TABLE `video_order` (`id` int(11) unsigned NOT NULL AUTO_INCREMENT,`user_id` int(11) DEFAULT NULL,`money` int(11) DEFAULT NULL,`title` varchar(32) DEFAULT NULL,`trade_no` varchar(64) DEFAULT NULL,`create_time` date DEFAULT NULL,PRIMARY KEY (`id`)) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;- 添加jdbc依赖
xxxxxxxxxx<dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>8.0.25</version></dependency>- 编码
xxxxxxxxxxpublic class MysqlSink extends RichSinkFunction<VideoOrder> {private Connection conn = null;private PreparedStatement ps = null;@Overridepublic void open(Configuration parameters) throws Exception {conn = DriverManager.getConnection("jdbc:mysql://localhost:3306/xd_order?useUnicode=true&characterEncoding=utf8&allowMultiQueries=true&serverTimezone=Asia/Shanghai", "root", "xdclass.net");String sql = "INSERT INTO `video_order` (`user_id`, `money`, `title`, `trade_no`, `create_time`) VALUES(?,?,?,?,?);";ps = conn.prepareStatement(sql);}@Overridepublic void close() throws Exception {if (conn != null) {conn.close();}if (ps != null) {ps.close();}}@Overridepublic void invoke(VideoOrder videoOrder, Context context) throws Exception {//给ps中的?设置具体值ps.setInt(1,videoOrder.getUserId());ps.setInt(2,videoOrder.getMoney());ps.setString(3,videoOrder.getTitle());ps.setString(4,videoOrder.getTradeNo());ps.setDate(5,new Date(videoOrder.getCreateTime().getTime()));ps.executeUpdate();}}
第3集 Flink 自定义的Sink 连接Mysql存储商品订单案例实战《下》
简介:Flink 自定义的SinkFunction 数据源输出案例实战
- Flink整合自定义Sink实战
xxxxxxxxxxDataStream<VideoOrder> videoOrderDS = env.addSource(new VideoOrderSource());videoOrderDS.addSink(new MysqlSink());
自定义MysqlSink
建议继承RichSinkFunction函数
- 用open()函数初始化JDBC连接
- invoke SQL预编译器等运行时环境
- close()函数做清理工作
如果选择继承SinkFunction,会在每次写入一条数据时都会创建一个JDBC连接
第4集 Flink 商品销量统计-实战Bahir Connetor实战存储 数据到Redis6.X
简介:Flink 实战Bahir Connetor 存储数据到Redis6.X实战
Flink怎么操作redis?
- 方式一:自定义sink
- 方式二:使用connector
Redis Sink 核心是RedisMapper 是一个接口,使用时要编写自己的redis操作类实现这个接口中的三个方法
- getCommandDescription 选择对应的数据结构和key名称配置
- getKeyFromData 获取key
- getValueFromData 获取value
使用
- 添加依赖
xxxxxxxxxx<dependency><groupId>org.apache.bahir</groupId><artifactId>flink-connector-redis_2.11</artifactId><version>1.0</version></dependency>编码
xxxxxxxxxxpublic class MyRedisSink implements RedisMapper<Tuple2<String, Integer>> {@Overridepublic RedisCommandDescription getCommandDescription() {return new RedisCommandDescription(RedisCommand.HSET, "VIDEO_ORDER_COUNTER");}@Overridepublic String getKeyFromData(Tuple2<String, Integer> value) {return value.f0;}@Overridepublic String getValueFromData(Tuple2<String, Integer> value) {return value.f1.toString();}}
第5集 Flink 商品销量统计-转换-分组-聚合-存储自定义的Redis Sink实战
简介:Flink 商品销量统计-转换-分组-聚合-存储自定义的Redis Sink实战
Redis环境说明 redis6
课程使用docker部署redis6.x
xxxxxxxxxxdocker run -d -p 6379:6379 redis
编码实战
xxxxxxxxxxpublic static void main(String[] args) throws Exception {//构建执行任务环境以及任务的启动的入口, 存储全局相关的参数StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();DataStream<VideoOrder> ds = env.fromElements(new VideoOrder("21312","java",32,5,new Date()),new VideoOrder("314","java",32,5,new Date()),new VideoOrder("542","springboot",32,5,new Date()),new VideoOrder("42","redis",32,5,new Date()),new VideoOrder("52","java",32,5,new Date()),new VideoOrder("523","redis",32,5,new Date()));//map转换,来一个记录一个,方便后续统计// DataStream<Tuple2<String,Integer>> mapDS = ds.map(new MapFunction<VideoOrder, Tuple2<String,Integer>>() {// @Override// public Tuple2<String, Integer> map(VideoOrder value) throws Exception {// return new Tuple2<>(value.getTitle(),1);// }// });//只是一对一记录而已,没必要使用flatMapDataStream<Tuple2<String,Integer>> mapDS = ds.flatMap(new FlatMapFunction<VideoOrder, Tuple2<String,Integer>>() {@Overridepublic void flatMap(VideoOrder value, Collector<Tuple2<String, Integer>> out) throws Exception {out.collect(new Tuple2<>(value.getTitle(),1));}});//key是返回的类型,value是分组key的类型; DataSet里面分组是groupBy, 流处理里面分组用 keyByKeyedStream<Tuple2<String,Integer>,String> keyByDS = mapDS.keyBy(new KeySelector<Tuple2<String,Integer>, String>() {@Overridepublic String getKey(Tuple2<String, Integer> value) throws Exception {return value.f0;}});//对各个组内的数据按照数量(value)进行聚合就是求sum, 1表示按照tuple中的索引为1的字段也就是按照数量进行聚合累加DataStream<Tuple2<String, Integer>> sumDS = keyByDS.sum(1);sumDS.print();FlinkJedisPoolConfig conf = new FlinkJedisPoolConfig.Builder().setHost("127.0.0.1").build();sumDS.addSink(new RedisSink<>(conf, new MyRedisSink()));//DataStream需要调用execute,可以取个名称env.execute("custom sink job");}
![]() 愿景:"让编程不再难学,让技术与生活更加有趣"
愿景:"让编程不再难学,让技术与生活更加有趣"
更多架构课程请访问 xdclass.net
第八章 玩转Flink里面核心Source Sink对接 Kafka Connetor实战
第1集 Kafka相关运行环境说明和必备基础知识点
简介:Kafka相关运行环境说明和必备基础知识点
大家自行搭建Kafka环境,如果不会kafka的话看视频
Docker快速部署kafka
xxxxxxxxxx#zkdocker run -d --name zookeeper -p 2181:2181 -t wurstmeister/zookeeper#kafkadocker run -d --name xdclass_kafka \-p 9092:9092 \-e KAFKA_BROKER_ID=0 \-e KAFKA_ZOOKEEPER_CONNECT=192.168.0.116:2181 \-e KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://192.168.0.116:9092 \-e KAFKA_LISTENERS=PLAINTEXT://0.0.0.0:9092 wurstmeister/kafka#进入容器内部,创建topicdocker exec -it 9b5070d79dfa /bin/bashcd /opt/kafkabin/kafka-topics.sh --create --zookeeper 192.168.0.116:2181 --replication-factor 1 --partitions 1 --topic xdclass-topic#创建生产者发送消息bin/kafka-console-producer.sh --broker-list localhost:9092 --topic xdclass-topic#运行一个消费者bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic xdclass-topic --from-beginning
特别强调,如果搭建失败或者kafka本身不会的,请看kafka专题视频,这个是必备!!!!
- Kafka专题:https://detail.tmall.com/item.htm?id=644733174351&skuId=4637463036426
- 不要Window操作docker,不兼容问题很多
- 使用阿里云服务器,开放网络安全组

第2集 Flink Source 读取消息队列Kafka连接器配置讲解
简介:Flink Source 读取消息队列Kafka连接器整合实战
之前自定义SourceFunction,Flink官方也有提供对接外部系统的,比如读取Kafka
flink官方提供的连接器
- 添加依赖
xxxxxxxxxx<dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-kafka_${scala.version}</artifactId><version>${flink.version}</version></dependency>
编写代码
- FlinkKafkaConsumer-》FlinkKafkaConsumerBase-》RichParallelSourceFunction(富函数-并行读取kafka多分区)
xxxxxxxxxxpublic static void main(String[] args) throws Exception {//构建执行任务环境以及任务的启动的入口, 存储全局相关的参数StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();Properties props = new Properties();//kafka地址props.setProperty("bootstrap.servers", "localhost:9092");//组名props.setProperty("group.id", "video-order-group");//字符串序列化和反序列化规则props.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");props.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");//offset重置规则props.setProperty("auto.offset.reset", "latest");//自动提交props.setProperty("enable.auto.commit", "true");props.setProperty("auto.commit.interval.ms", "2000");//有后台线程每隔10s检测一下Kafka的分区变化情况props.setProperty("flink.partition-discovery.interval-millis","10000");FlinkKafkaConsumer<String> consumer =new FlinkKafkaConsumer<>("xdclass-topic", new SimpleStringSchema(), props);//设置从记录的消费者组内的offset开始消费consumer.setStartFromGroupOffsets();DataStream<String> ds = env.addSource(consumer);ds.print();//DataStream需要调用execute,可以取个名称env.execute("custom source job");}
第3集 Flink Sink输出消息队列Kafka连接器整合实战
简介:Flink Sink读取消息队列Kafka连接器整合实战
- Sink输出配置
xxxxxxxxxxpublic static void main(String[] args) throws Exception {//构建执行任务环境以及任务的启动的入口, 存储全局相关的参数StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();Properties props = new Properties();//kafka地址props.setProperty("bootstrap.servers", "localhost:9092");//组名props.setProperty("group.id", "video-order-group");//字符串序列化和反序列化规则props.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");props.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");//offset重置规则props.setProperty("auto.offset.reset", "latest");//自动提交props.setProperty("enable.auto.commit", "true");props.setProperty("auto.commit.interval.ms", "2000");//有后台线程每隔10s检测一下Kafka的分区变化情况props.setProperty("flink.partition-discovery.interval-millis","10000");FlinkKafkaConsumer<String> consumer =new FlinkKafkaConsumer<>("xdclass-topic", new SimpleStringSchema(), props);//设置从记录的消费者组内的offset开始消费, 如果没有记录从 auto.offset.reset 配置开始消费consumer.setStartFromGroupOffsets();DataStream<String> ds = env.addSource(consumer);ds.print();//处理,拼接字符串DataStream<String> mapDS = ds.map(new MapFunction<String, String>() {@Overridepublic String map(String value) throws Exception {return "小滴课堂:"+value;}});//输出FlinkKafkaProducer<String> kafkaSink = new FlinkKafkaProducer<>("xdclass-order", new SimpleStringSchema(), props);mapDS.addSink(kafkaSink);env.execute();//DataStream需要调用execute,可以取个名称env.execute("custom source job");}
- 进入docker查看消息
xxxxxxxxxx#创建生产者发送消息bin/kafka-console-producer.sh --broker-list localhost:9092 --topic xdclass-topic#运行一个消费者bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic xdclass-order --from-beginning
![]() 愿景:"让编程不再难学,让技术与生活更加有趣"
愿景:"让编程不再难学,让技术与生活更加有趣"
更多架构课程请访问 xdclass.net
第九章 玩转Flink Core Api常用Transformation算子 多案例实战
第1集 Flink 里面的Map和FlatMap 算子实战订单转换
简介:Flink 里面的Map和FlatMap 算子实战
需求:多数算子,我们会用订单 转换-过滤-分组-统计 来实现
- 这样大家更加明白应用场景,比如应用到多个方面等
结果类型 idea自动提示
- 算子后 .var 回车 java类型
- 算子后 .val 回车 scala类型
什么是java里面的Map操作
- 一对一 转换对象
xxxxxxxxxxDataStream<VideoOrder> ds = env.fromElements(new VideoOrder("253","java",30,15,new Date()),new VideoOrder("323","java",30,5,new Date()),new VideoOrder("42","java",30,5,new Date()),new VideoOrder("543","springboot",21,5,new Date()),new VideoOrder("423","redis",40,5,new Date()),new VideoOrder("15","redis",40,5,new Date()),new VideoOrder("312","springcloud",521,5,new Date()),new VideoOrder("125","kafka",1,55,new Date()));// map转换,来一个记录一个,方便后续统计DataStream<Tuple2<String,Integer>> mapDS = ds.map(new MapFunction<VideoOrder, Tuple2<String,Integer>>() {@Overridepublic Tuple2<String, Integer> map(VideoOrder value) throws Exception {return new Tuple2<>(value.getTitle(),1);}});mapDS.print();
什么是java里面的FlatMap操作
- 一对多转换对象
xxxxxxxxxx//只是一对一记录而已,没必要使用flatMap// FlatMapFunction<String, String>, key是输入类型,value是Collector响应的收集的类型,看源码注释,也是 DataStream<String>里面泛型类型DataStream<Tuple2<String,Integer>> mapDS = ds.flatMap(new FlatMapFunction<VideoOrder, Tuple2<String,Integer>>() {@Overridepublic void flatMap(VideoOrder value, Collector<Tuple2<String, Integer>> out) throws Exception {out.collect(new Tuple2<>(value.getTitle(),1));}});
第2集 Flink 里面的RichMap和RichFlatMap 算子实战
简介:Flink 里面的RichMap和RichFlatMap 算子实战
Rich相关的api更丰富,多了Open、Close方法,用于初始化连接等
RichXXX相关Open、Close、setRuntimeContext等 API方法会根据并行度进行操作的
- 比如并行度是4,那就有4次触发对应的open/close方法等,是4个不同subtask
- 比如 RichMapFunction、RichFlatMapFunction、RichSourceFunction等
xxxxxxxxxx//构建执行任务环境以及任务的启动的入口, 存储全局相关的参数StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);DataStream<VideoOrder> ds = env.fromElements(new VideoOrder("253","java",30,15,new Date()),new VideoOrder("323","java",30,5,new Date()),new VideoOrder("42","java",30,5,new Date()),new VideoOrder("543","springboot",21,5,new Date()),new VideoOrder("423","redis",40,5,new Date()),new VideoOrder("15","redis",40,5,new Date()),new VideoOrder("312","springcloud",521,5,new Date()),new VideoOrder("125","kafka",1,55,new Date()));DataStream<Tuple2<String,Integer>> mapDS = ds.map(new RichMapFunction<VideoOrder, Tuple2<String, Integer>>() {@Overridepublic void open(Configuration parameters) throws Exception {System.out.println("open====");}@Overridepublic void close() throws Exception {System.out.println("close====");}@Overridepublic Tuple2<String, Integer> map(VideoOrder value) throws Exception {return new Tuple2<>(value.getTitle(),1);}});DataStream<Tuple2<String,Integer>> flatMapDS = ds.flatMap(new RichFlatMapFunction<VideoOrder, Tuple2<String,Integer>>() {@Overridepublic void open(Configuration parameters) throws Exception {System.out.println("open====");}@Overridepublic void close() throws Exception {System.out.println("close====");}@Overridepublic void flatMap(VideoOrder value, Collector<Tuple2<String, Integer>> out) throws Exception {out.collect(new Tuple2<>(value.getTitle(),1));}});
第3集 Flink 里面的KeyBy分组概念讲解+订单统计实战
简介:Flink 里面的KeyBy分组概念讲解+订单统计实战
KeyBy分组概念介绍
- keyBy是把数据流按照某个字段分区
- keyBy后是相同的数据放到同个组里面,再进行组内统计
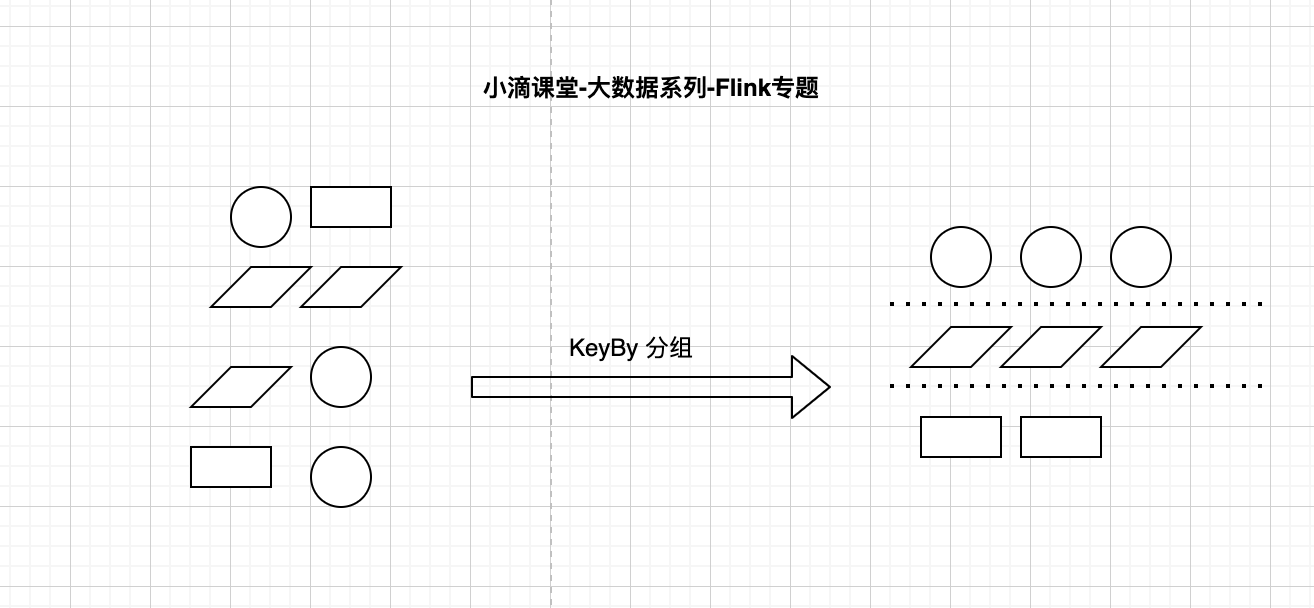
xxxxxxxxxxKeyedStream<VideoOrder, String> videoOrderStringKeyedStream = filterDS.keyBy(new KeySelector<VideoOrder, String>() {@Overridepublic String getKey(VideoOrder value) throws Exception {return value.getTitle();}});DataStream<VideoOrder> sumDS = videoOrderStringKeyedStream.sum("money");sumDS.print();
常规的数据流转
- DataStream->keyBy操作->KeyStream->window操作->windowStream->聚合操作->DataStream
注意: KeyBy后的聚合函数,只处理当前分组后组内的数据,不同组内数据互不影响
第4集 Flink 里面的filter和sum 算子实战电商订单成交价统计
简介:Flink 里面的filter和sum 算子实战电商订单成交价统计
- filter过滤
- sum 算子
- 链式调用
xxxxxxxxxxpublic static void main(String[] args) throws Exception {//构建执行任务环境以及任务的启动的入口, 存储全局相关的参数StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);env.setParallelism(1);DataStreamSource<VideoOrder> ds = env.addSource(new VideoOrderSourceV2());DataStream<VideoOrder> sumDS = ds.filter(new FilterFunction<VideoOrder>() {@Overridepublic boolean filter(VideoOrder value) throws Exception {return value.getMoney() > 20;}}).keyBy(new KeySelector<VideoOrder, String>() {@Overridepublic String getKey(VideoOrder value) throws Exception {return value.getTitle();}}).sum("money");sumDS.print();//DataStream需要调用execute,可以取个名称env.execute("map job");}
第5集 Flink 核心API Reduce聚合讲解和sum区别应用场景
简介: Flink 核心API Reduce聚合讲解和sum区别应用场景
reduce函数
- keyBy分组后聚合统计sum和reduce实现一样的效果
- 例子
xxxxxxxxxxvideoOrderStringKeyedStream.reduce(new ReduceFunction<VideoOrder>() {@Overridepublic VideoOrder reduce(VideoOrder value1, VideoOrder value2) throws Exception {VideoOrder videoOrder = new VideoOrder();videoOrder.setTitle(value1.getTitle());videoOrder.setMoney(value1.getMoney() + value2.getMoney());return videoOrder;}});reduce.print();value1是历史对象,value2是加入统计的对象,所以value1.f1是历史值,value2.f1是新值,不断累加sum区别
sum("xxx")使用的时候,如果是tuple元组则用序号,POJO则用属性名称
keyBy分组后聚合统计sum和reduce实现一样的效果
sum是简单聚合,reduce是可以自定义聚合,aggregate支持复杂的自定义聚合
第6集 Flink 核心API maxBy-max-minBy-min 区别和应用
简介: Flink 核心API maxBy-max-minBy-min 区别和应用
如果是用了keyby,在后续算子要用maxby,minby类型,才可以再分组里面找对应的数据
- 如果是用max、min等,就不确定是哪个key中选了
- 如果是keyBy的是对象的某个属性,则分组用max/min聚合统计,只有聚合的字段会更新,其他字段还是旧的,导致对象不准确
- 需要用maxby/minBy才对让整个对象的属性都是最新的
例子
xxxxxxxxxx//并行度不为1才看得出效果//env.setParallelism(1);DataStream<VideoOrder> ds = env.fromElements(new VideoOrder("1","java",31,15,new Date()),new VideoOrder("2","java",32,45,new Date()),new VideoOrder("3","java",33,52,new Date()),new VideoOrder("4","springboot",21,5,new Date()),new VideoOrder("5","redis",41,52,new Date()),new VideoOrder("6","redis",40,15,new Date()),new VideoOrder("7","kafka",1,55,new Date()));SingleOutputStreamOperator<VideoOrder> maxByDS = ds.keyBy(new KeySelector<VideoOrder, String>() {@Overridepublic String getKey(VideoOrder value) throws Exception {return value.getTitle();}}).maxBy("money");SingleOutputStreamOperator<VideoOrder> maxDS = ds.keyBy(new KeySelector<VideoOrder, String>() {@Overridepublic String getKey(VideoOrder value) throws Exception {return value.getTitle();}}).max("money");//maxByDS.print("maxByDS:");maxDS.print("maxDS:");
- KeyBy后可以用KeyedProcessFunction,更底层的API,有processElement和onTimer函数
![]() 愿景:"让编程不再难学,让技术与生活更加有趣"
愿景:"让编程不再难学,让技术与生活更加有趣"
更多架构课程请访问 xdclass.net
第十章 关于Flink滑动-滚动时间窗和触发器你知道多少
第1集 Flink 核心-Window窗口介绍和应用场景
简介: Flink 核心Window窗口介绍和应用场景
先说下:本章内容很重要!!!!!!!!
文档地址
- https://ci.apache.org/projects/flink/flink-docs-release-1.13/zh/docs/dev/datastream/operators/windows
- Windows are at the heart of processing infinite streams(Window是处理无限数据量的核心)
背景
- 数据流是一直源源不断产生,业务需要聚合统计使用,比如每10秒统计过去5分钟的点击量、成交额等
- Windows 就可以将无限的数据流拆分为有限大小的“桶 buckets”,然后程序可以对其窗口内的数据进行计算
- 窗口认为是Bucket桶,一个窗口段就是一个桶,比如8到9点是一个桶,9到10点是一个桶
分类
time Window 时间窗口,即按照一定的时间规则作为窗口统计
- time-tumbling-window 时间滚动窗口 (用的多)
- time-sliding-window 时间滑动窗口 (用的多)
- session WIndow 会话窗口,即一个会话内的数据进行统计,相对少用
count Window 数量窗口,即按照一定的数据量作为窗口统计,相对少用
窗口属性
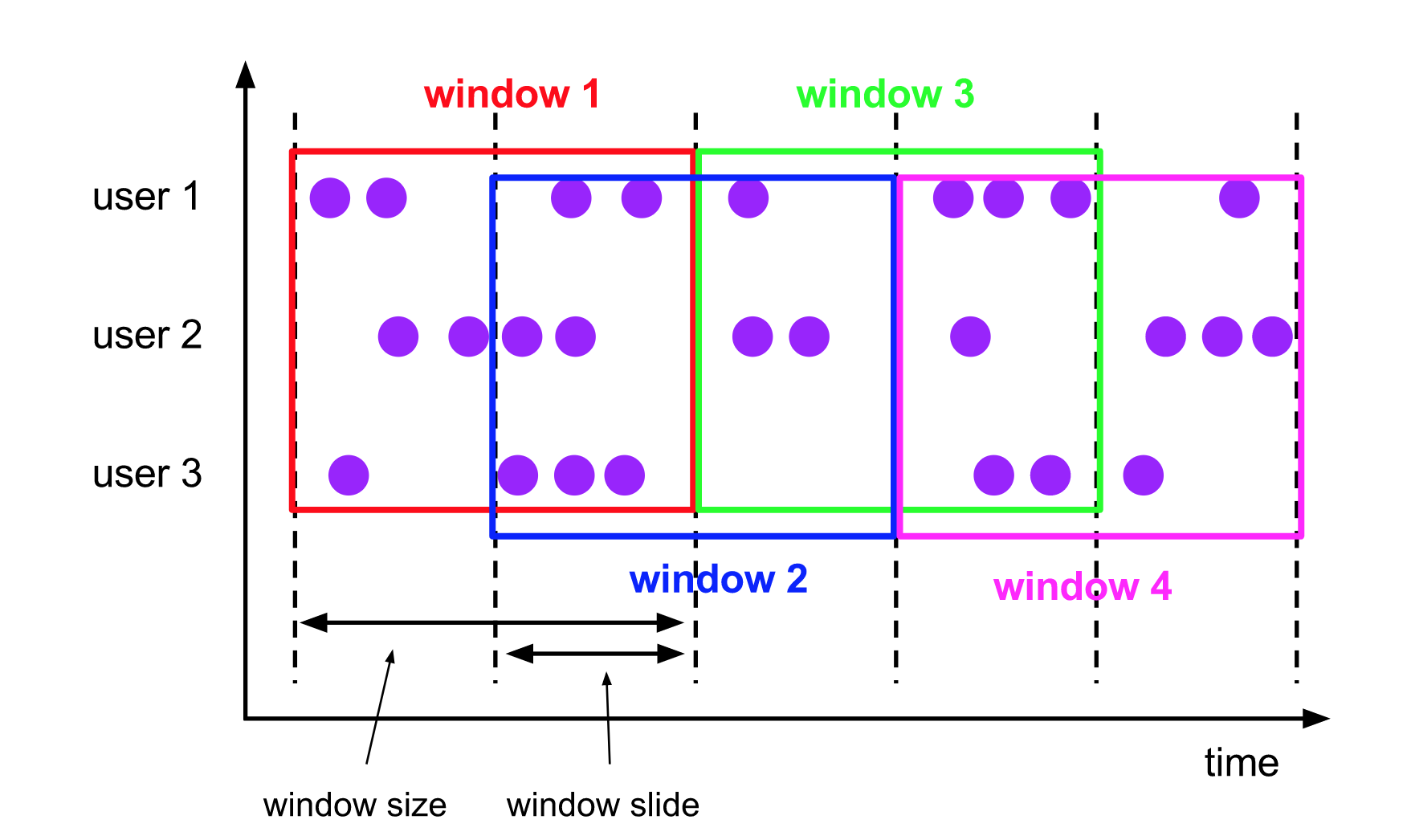
滑动窗口 Sliding Windows
- 窗口具有固定大小
- 窗口数据有重叠
- 例子:每10s统计一次最近1min内的订单数量
滚动窗口 Tumbling Windows
- 窗口具有固定大小
- 窗口数据不重叠
- 例子:每10s统计一次最近10s内的订单数量
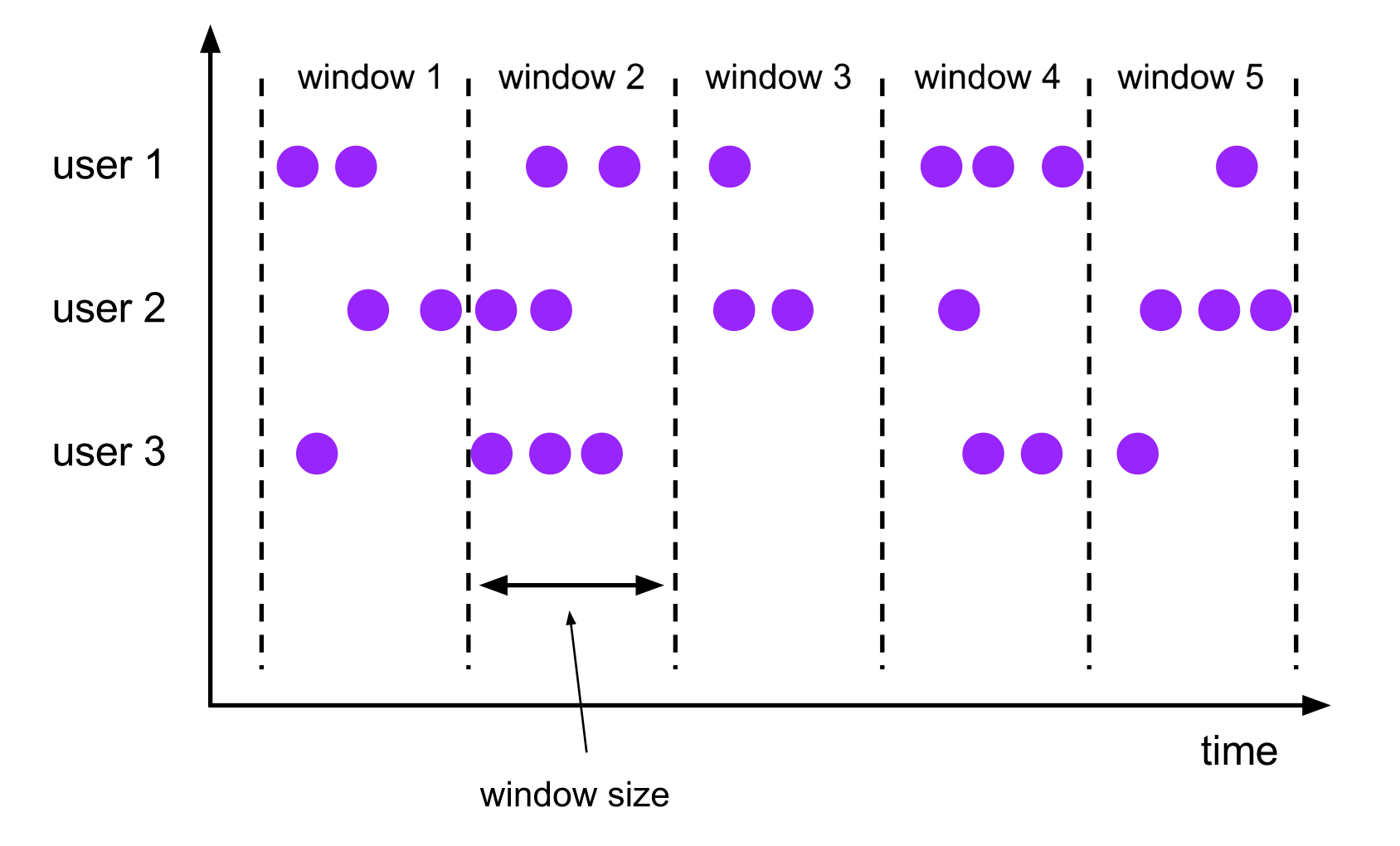
窗口大小size 和 滑动间隔 slide
- tumbling-window:滚动窗口: size=slide,如:每隔10s统计最近10s的数据
- sliding-window:滑动窗口: size>slide,如:每隔5s统计最近10s的数据
- size<slide的时候,如每隔15s统计最近10s的数据,那么中间5s的数据会丢失,所以开发中不用
第2集 Flink 核心-Window 窗口API和使用流程介绍
简介: Flink 核心-Window 窗口API和使用流程介绍
什么情况下才可以使用WindowAPI
- 有keyBy 用 window() api
- 没keyBy 用 windowAll() api ,并行度低
- 方括号 ([…]) 中的命令是可选的,允许用多种不同的方式自定义窗口逻辑

注意
一个窗口内 的是左闭右开
countWindow没过期,但timeWindow在1.12过期,统一使用window;
窗口分配器 Window Assigners
- 定义了如何将元素分配给窗口,负责将每条数据分发到正确的 window窗口上
- window() 的参数是一个 WindowAssigner,flink本身提供了Tumbling、Sliding 等Assigner
窗口触发器 trigger
- 用来控制一个窗口是否需要被触发
- 每个 窗口分配器WindowAssigner 都有一个默认触发器,也支持自定义触发器
窗口 window function ,对窗口内的数据做啥?
定义了要对窗口中收集的数据做的计算操作
增量聚合函数
xxxxxxxxxxaggregate(agg函数,WindowFunction(){ })- 窗口保存临时数据,每进入一个新数据,会与中间数据累加,生成新的中间数据,再保存到窗口中
- 常见的增量聚合函数有 reduceFunction、aggregateFunction
- min、max、sum 都是简单的聚合操作,不需要自定义规则
xxxxxxxxxxAggregateFunction<IN, ACC, OUT>IN是输入类型,ACC是中间聚合状态类型,OUT是输出类型,是聚合统计当前窗口的数据全窗口函数
xxxxxxxxxxapply(new processWindowFunction(){ })- 窗口先缓存该窗口所有元素,等窗口的全部数据收集起来后再触发条件计算
- 常见的全窗口聚合函数 windowFunction(未来可能弃用)、processWindowFunction(可以获取到窗口上下文 更多信息)
xxxxxxxxxxIN是输入类型,OUT是输出类型,KEY是分组类型,W是时间窗WindowFunction<IN, OUT, KEY, W extends Window>如果想处理每个元素更底层的API的时候用
xxxxxxxxxx//对数据进行解析 ,process对每个元素进行处理,相当于 map+flatMap+filterprocess(new KeyedProcessFunction(){processElement、onTimer})
第3集 Tumbling-Window滚动时间窗介绍和案例实战
简介: Tumbling-Window滚动时间窗介绍和案例实战
滚动窗口 Tumbling Windows
- 窗口具有固定大小
- 窗口数据不重叠
比如指定了一个5分钟大小的滚动窗口,无限流的数据会根据时间划分为[0:00, 0:05)、[0:05, 0:10)、[0:10, 0:15)等窗口
案例实战(可以单一个数据测试,后续再讲时间语义)
xxxxxxxxxx//方便调试,POJO类增加对象产生信息public String toString() {DateTimeFormatter formatter = DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss");ZoneId zoneId = ZoneId.systemDefault();return "VideoOrder{" +"tradeNo='" + tradeNo + '\'' +", title='" + title + '\'' +", money=" + money +", userId=" + userId +", createTime=" + formatter.format(createTime.toInstant().atZone(zoneId)) +'}';}//VideoOrderSourceV2System.out.println("产生:"+videoOrder.getTitle()+",价格:"+videoOrder.getMoney()+", 时间:"+videoOrder.getCreateTime());env.setParallelism(1);DataStream<VideoOrder> ds = env.addSource(new VideoOrderSourceV2());SingleOutputStreamOperator<VideoOrder> sumDS = ds.keyBy(new KeySelector<VideoOrder, String>() {@Overridepublic String getKey(VideoOrder value) throws Exception {return value.getTitle();}}).window(TumblingProcessingTimeWindows.of(Time.seconds(5))).sum("money");sumDS.print();
第4集 Sliding -Window滑动时间窗介绍和案例实战
简介: Sliding -Window滑动时间窗介绍和案例实战
滑动窗口 Sliding Windows
- 窗口具有固定大小
- 窗口数据有重叠
- 例子:每10s统计一次最近1min内的订单数量
案例实战
- 每5秒统计过去20秒的不同视频的订单总价
xxxxxxxxxxDataStream<VideoOrder> sumDS = keyByDS.window(SlidingProcessingTimeWindows.of(Time.seconds(20),Time.seconds(5))).sum("money");
第5集 基于数量的Count Window窗口介绍和案例实战
简介:数量Count Window窗口介绍和案例实战
基于数量的滚动窗口, 滑动计数窗口
案例:
- 统计分组后同个key内的数据超过5次则进行统计 countWindow(5)
- 只要有2个数据到达后就可以往后统计5个数据的值, countWindow(5, 2)
xxxxxxxxxx//数据源 sourceDataStream<VideoOrder> ds = env.addSource(new VideoOrderSourceV2());KeyedStream<VideoOrder, String> keyByDS = ds.keyBy(new KeySelector<VideoOrder, String>() {@Overridepublic String getKey(VideoOrder value) throws Exception {return value.getTitle();}});//分组后的组内数据超过5个则触发//DataStream<VideoOrder> sumDS = keyByDS.countWindow(5).sum("money");//分组后的组内数据超过3个则触发统计过去的5个数据DataStream<VideoOrder> sumDS = keyByDS.countWindow(5,3).sum("money");sumDS.print();
![]() 愿景:"让编程不再难学,让技术与生活更加有趣"
愿景:"让编程不再难学,让技术与生活更加有趣"
更多架构课程请访问 xdclass.net
第十一章 核心知识-Flink 增量聚合和全窗口函数你知道多少
第1集 Flink里面你需要知道的AggregateFunction增量聚合函数知识
简介: Flink里面你需要知道的AggregateFunction增量聚合函数知识
窗口 window function ,对窗口内的数据做啥?
定义了要对窗口中收集的数据做的计算操作
增量聚合函数
xxxxxxxxxxaggregate(agg函数,WindowFunction(){ })- 窗口保存临时数据,每进入一个新数据,会与中间数据累加,生成新的中间数据,再保存到窗口中
- 常见的增量聚合函数有 reduceFunction、aggregateFunction
- min、max、sum 都是简单的聚合操作,不需要自定义规则
xxxxxxxxxxAggregateFunction<IN, ACC, OUT>IN是输入类型,ACC是中间聚合状态类型,OUT是输出类型,是聚合统计当前窗口的数据
案例实战-滚动时间窗
xxxxxxxxxxSingleOutputStreamOperator<VideoOrder> aggDS = ds.keyBy(new KeySelector<VideoOrder, String>() {@Overridepublic String getKey(VideoOrder value) throws Exception {return value.getTitle();}}).window(TumblingProcessingTimeWindows.of(Time.seconds(5))).aggregate(new AggregateFunction<VideoOrder, VideoOrder, VideoOrder>() {//累加器初始化@Overridepublic VideoOrder createAccumulator() {VideoOrder videoOrder = new VideoOrder();return videoOrder;}//聚合方式@Overridepublic VideoOrder add(VideoOrder value, VideoOrder accumulator) {accumulator.setMoney(value.getMoney()+accumulator.getMoney());accumulator.setTitle(value.getTitle());if(accumulator.getCreateTime()==null){accumulator.setCreateTime(value.getCreateTime());}return accumulator;}//获取结果@Overridepublic VideoOrder getResult(VideoOrder accumulator) {return accumulator;}//合并内容,一般不用@Overridepublic VideoOrder merge(VideoOrder a, VideoOrder b) {VideoOrder videoOrder = new VideoOrder();videoOrder.setMoney(a.getMoney()+b.getMoney());return videoOrder;}});aggDS.print();
第2集 Flink里面你需要知道的WindowFunction全窗口函数知识
简介: Flink里面你需要知道的WindowFunction全窗口函数知识
全窗口函数
xxxxxxxxxxapply(new WindowFunction(){ })- 窗口先缓存该窗口所有元素,等窗口的全部数据收集起来后再触发条件计算
- 常见的全窗口聚合函数 windowFunction(未来可能弃用)、processWindowFunction(可以获取到窗口上下文 更多信息,包括窗口信息)
xxxxxxxxxxIN是输入类型,OUT是输出类型,KEY是分组类型,W是时间窗WindowFunction<IN, OUT, KEY, W extends Window>案例实战
xxxxxxxxxxSingleOutputStreamOperator<VideoOrder> aggDS = ds.keyBy(new KeySelector<VideoOrder, String>() {@Overridepublic String getKey(VideoOrder value) throws Exception {return value.getTitle();}}).window(SlidingProcessingTimeWindows.of(Time.seconds(10),Time.seconds(5))).apply( new WindowFunction<VideoOrder, VideoOrder, String, TimeWindow>() {@Overridepublic void apply(String key, TimeWindow window, Iterable<VideoOrder> input, Collector<VideoOrder> out) throws Exception {List<VideoOrder> list = IteratorUtils.toList(input.iterator());int total =list.stream().collect(Collectors.summingInt(VideoOrder::getMoney)).intValue();VideoOrder videoOrder = new VideoOrder();videoOrder.setMoney(total);videoOrder.setCreateTime(list.get(0).getCreateTime());videoOrder.setTitle(list.get(0).getTitle());out.collect(videoOrder);}});
第3集 Flink里面你需要知道的processWindowFunction全窗口函数知识
简介: Flink里面你需要知道的processWindowFunction全窗口函数知识
全窗口函数
xxxxxxxxxxprocess(new ProcessWindowFunction(){})- 窗口先缓存该窗口所有元素,等窗口的全部数据收集起来后再触发条件计算
- 常见的全窗口聚合函数 windowFunction(未来可能弃用)、processWindowFunction(可以获取到窗口上下文 更多信息,包括窗口信息)
xxxxxxxxxxIN是输入类型,OUT是输出类型,KEY是分组类型,W是时间窗ProcessWindowFunction<IN, OUT, KEY, W extends Window>案例实战
xxxxxxxxxxSingleOutputStreamOperator<VideoOrder> aggDS = ds.keyBy(new KeySelector<VideoOrder, String>() {@Overridepublic String getKey(VideoOrder value) throws Exception {return value.getTitle();}}).window(SlidingProcessingTimeWindows.of(Time.seconds(10),Time.seconds(5))).process(new ProcessWindowFunction<VideoOrder, VideoOrder, String, TimeWindow>() {@Overridepublic void process(String key, Context context, Iterable<VideoOrder> elements, Collector<VideoOrder> out) throws Exception {List<VideoOrder> list = IteratorUtils.toList(elements.iterator());int total =list.stream().collect(Collectors.summingInt(VideoOrder::getMoney)).intValue();VideoOrder videoOrder = new VideoOrder();videoOrder.setMoney(total);videoOrder.setTitle(list.get(0).getTitle());videoOrder.setCreateTime(list.get(0).getCreateTime());out.collect(videoOrder);}});
窗口函数对比
增量聚合
xxxxxxxxxxaggregate(new AggregateFunction(){});
全窗口聚合
xxxxxxxxxxapply(new WindowFunction(){})xxxxxxxxxxprocess(new ProcessWindowFunction(){}) //比上面这个强
![]() 愿景:"让编程不再难学,让技术与生活更加有趣"
愿景:"让编程不再难学,让技术与生活更加有趣"
更多架构课程请访问 xdclass.net
第十二章 迟到无序数据处理-时间概念和watermark的强大之处
第1集 Flink的多种时间概念介绍和应用场景
简介: Flink的多种时间概念介绍和应用场景
背景
- 前面我们使用了Window窗口函数,flink怎么知道哪个是字段是对应的时间呢?
- 由于网络问题,数据先产生,但是乱序延迟了,那属于哪个时间窗呢?

- Flink里面定义窗口,可以引用不同的时间概念
Flink里面时间分类
事件时间EventTime(重点关注)
- 事件发生的时间
- 事件时间是每个单独事件在其产生进程上发生的时间,这个时间通常在记录进入 Flink 之前记录在对象中
- 在事件时间中,时间值 取决于数据产生记录的时间,而不是任何Flink机器上的
进入时间 IngestionTime
- 事件到进入Flink
处理时间ProcessingTime
事件被flink处理的时间
指正在执行相应操作的机器的系统时间
是最简单的时间概念,不需要流和机器之间的协调,它提供最佳性能和最低延迟
但是在分布式和异步环境中,处理时间有不确定性,存在延迟或乱序问题
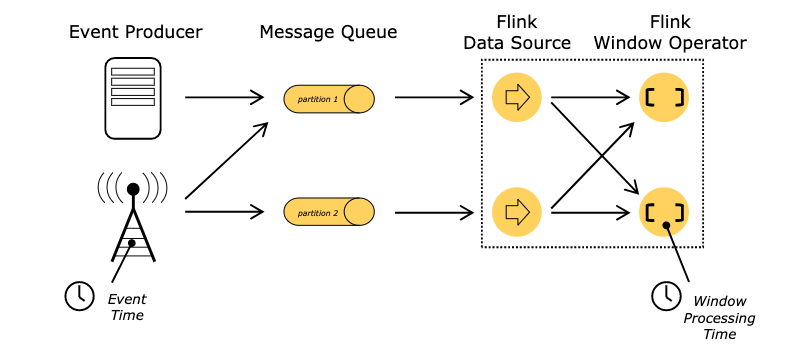
大家的疑惑
- 事件时间已经能够解决所有的问题了,那为何还要用处理时间呢????
- 处理时间由于不用考虑事件的延迟与乱序,所以处理数据的速度高效
- 如果一些应用比较重视处理速度而非准确性,那么就可以使用处理时间,但结果具有不确定性
- 事件时间有延迟,但是能够保证处理的结果具有准确性,并且可以处理延迟甚至无序的数据
举个例子
小滴课堂-老王 做了一个电商平台买 "超短男装衣服",如果要统计10分钟内成交额,你认为是哪个时间比较好?
- (EventTime) 下单支付时间是2022-11-11 01-01-01
- (IngestionTime ) 进入Flink时间2022-11-11 01-03-01(网络拥堵、延迟)
- (ProcessingTime)进入窗口时间2022-11-11 01-31-01(网络拥堵、延迟)

第2集 Flink乱序延迟时间处理-Watermark讲解《上》
简介: Flink乱序延迟时间处理-Watermark讲解
背景
一般我们都是用EventTime事件时间进行处理统计数据
但数据由于网络问题延迟、乱序到达会导致窗口计算数据不准确
需求:比如时间窗是 [12:01:01,12:01:10 ) ,但是有数据延迟到达
- 当 12:01:10 秒数据到达的时候,不立刻触发窗口计算
- 而是等一定的时间,等迟到的数据来后再关闭窗口进行计算
生活中的例子
小滴课堂:每天10点后就是迟到,需要扣工资
老王上班 路途遥远(延迟) 经常迟到
- HR就规定迟到5分钟后就罚款100元(5分钟就是watermark)
- 迟到30分钟就是上午事假处理 (5~30分就是 allowLateness )
- 不请假都是要来的 (超过30分钟就是侧输出流,sideOutPut兜底)
超过5分钟就不用来了吗?还是要来的继续工作的,不然今天上午工资就没了
那如果迟到30分钟呢? 也要来的,不然就容易产生更大的问题,缺勤开除。。。。

Watermark 水位线介绍
由flink的某个operator操作生成后,就在整个程序中随event数据流转
- With Periodic Watermarks(周期生成,可以定义一个最大允许乱序的时间,用的很多)
- With Punctuated Watermarks(标点水位线,根据数据流中某些特殊标记事件来生成,相对少)
衡量数据是否乱序的时间,什么时候不用等早之前的数据
是一个全局时间戳,不是某一个key下的值
是一个特殊字段,单调递增的方式,主要是和数据本身的时间戳做比较
用来确定什么时候不再等待更早的数据了,可以触发窗口进行计算,忍耐是有限度的,给迟到的数据一些机会
注意
- Watermark 设置太小会影响数据准确性,设置太大会影响数据的实时性,更加会加重Flink作业的负担
- 需要经过测试,和业务相关联,得出一个较合适的值即可
窗口触发计算的时机
watermark之前是按照窗口的关闭时间点计算的 [12:01:01,12:01:10 )
watermark之后,触发计算的时机
- 窗口内有数据
- Watermaker >= Window EndTime窗口结束时间
触发计算后,其他窗口内数据再到达也被丢弃
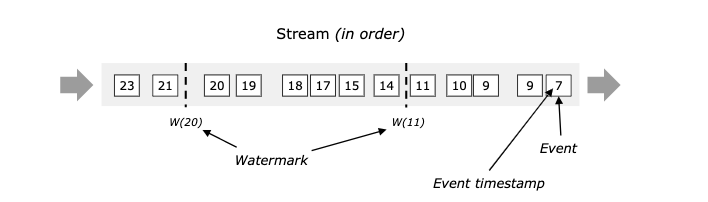
Watermaker = 当前计算窗口最大的事件时间 - 允许乱序延迟的时间
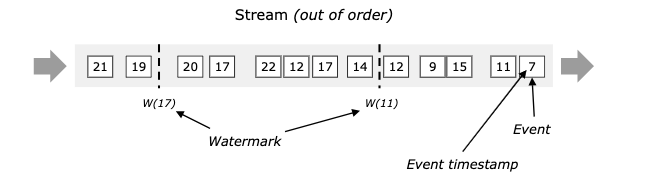
- 数据流中的事件是有序
- 数据流中的事件是无序
第3集 Flink乱序延迟时间处理-Watermark讲解《下》
简介: Flink乱序延迟时间处理-Watermark讲解
案例
window大小为10s,窗口是W1 [23:12:00~23:12:10) 、 W2[23:12:10~23:12:20)
- 下面是数据的event time
- 数据A 23:12:07
- 数据B 23:12:11
- 数据C 23:12:08
- 数据D 23:12:17
- 数据E 23:12:09
没加入watermark,由上到下进入flink
- 数据B到了之后,W1就进行了窗口计算,数据只有A
- 数据C 迟到了3秒,到了之后,由于W1已经计算了,所以就丢失了数据C
加入watermark, 允许5秒延迟乱序,由上到下进入flink
数据A到达
- watermark = 12:07 - 5 = 12:02 < 12:10 ,所以不触发W1计算, A属于W1
数据B到达
- watermark = max{ 12:11, 12:07} - 5 = 12:06 < 12:10 ,所以不触发W1计算, B属于W2
数据C到达
- watermark = max{12:08, 12:11, 12:07} - 5 = 12:06 < 12:10 ,所以不触发W1计算, C属于W1
数据D到达
- watermark = max{12:17, 12:08, 12:11, 12:07} - 5 = 12:12 > 23:12:10 , 触发W1计算, D属于W2
数据E到达
- watermark = max{12:09, 12:17, 12:08, 12:11, 12:07} - 5 = 12:12 > 23:12:10 , 之前已触发W1计算, 所以丢失了E数据,
Watermaker 计算 = 当前计算窗口最大的事件时间 - 允许乱序延迟的时间
什么时候触发W1窗口计算
Watermaker >= Window EndTime窗口结束时间
当前计算窗口最大的事件时间 - 允许乱序延迟的时间 >= Window EndTime窗口结束时间
第4集 Watermark+Window编码实战-分类统计电商订单成交额
简介: Flink重点组合-Watermark+Window编码实战-分类统计电商订单成交额
需求
- 分组统计不同视频的成交总价
- 数据有乱序延迟,允许3秒的时间
- 时间工具类
xxxxxxxxxx/*** date 转 字符串** @param time* @return*/public static String format(long timestamp) {DateTimeFormatter formatter = DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss");ZoneId zoneId = ZoneId.systemDefault();String timeStr = formatter.format(new Date(timestamp).toInstant().atZone(zoneId));return timeStr;}/*** 字符串 转 date** @param time* @return*/public static Date strToDate(String time) {DateTimeFormatter formatter = DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss");LocalDateTime localDateTime = LocalDateTime.parse(time, formatter);return Date.from(localDateTime.atZone(ZoneId.systemDefault()).toInstant());}
- 编写代码
xxxxxxxxxx/构建执行任务环境以及任务的启动的入口, 存储全局相关的参数StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);DataStream<String> ds = env.socketTextStream("127.0.0.1",8888);DataStream<Tuple3<String, String,Integer>> flatMapDS = ds.flatMap(new FlatMapFunction<String, Tuple3<String, String, Integer>>() {@Overridepublic void flatMap(String value, Collector<Tuple3<String, String,Integer>> out) throws Exception {String[] arr = value.split(",");out.collect(Tuple3.of(arr[0], arr[1],Integer.parseInt(arr[2])));}});SingleOutputStreamOperator<Tuple3<String, String,Integer>> watermakerDS = flatMapDS.assignTimestampsAndWatermarks(WatermarkStrategy//指定最大允许的延迟/乱序 时间.<Tuple3<String, String,Integer>>forBoundedOutOfOrderness(Duration.ofSeconds(3)).withTimestampAssigner((event, timestamp) -> {//指定POJO的事件时间列return TimeUtil.strToDate(event.f1).getTime();}));SingleOutputStreamOperator<String> sumDS = watermakerDS.keyBy(new KeySelector<Tuple3<String, String,Integer>, String>() {@Overridepublic String getKey(Tuple3<String, String,Integer> value) throws Exception {return value.f0;}}).window(TumblingEventTimeWindows.of(Time.seconds(10))).apply(new WindowFunction<Tuple3<String, String,Integer>, String, String, TimeWindow>() {@Overridepublic void apply(String key, TimeWindow window, Iterable<Tuple3<String, String,Integer>> input, Collector<String> out) throws Exception {//存放窗口的数据的事件时间List<String> eventTimeList = new ArrayList<>();int total = 0;for (Tuple3<String, String,Integer> order : input) {eventTimeList.add(order.f1);total = total+order.f2;}String outStr = String.format("分组key:%s,聚合值:%s,窗口开始结束:[%s~%s),窗口所有事件时间:%s", key,total, TimeUtil.format(window.getStart()),TimeUtil.format(window.getEnd()), eventTimeList);out.collect(outStr);}});sumDS.print();env.execute("watermark job");
第5集 分类统计电商订单成交额-SocketStream数据测试实战
简介: Flink实战-分类统计电商订单成交额-SocketStream数据测试实战
测试数据
窗口 [23:12:00 ~ 23:12:10) | [23:12:10 ~ 23:12:20)
触发窗口计算条件
- 窗口内有数据
- watermark >= 窗口endtime
- 即 当前计算窗口最大的事件时间 - 允许乱序延迟的时间 >= Window EndTime窗口结束时间
xxxxxxxxxxjava,2022-11-11 23:12:07,10java,2022-11-11 23:12:11,10java,2022-11-11 23:12:08,10mysql,2022-11-11 23:12:13,10java,2022-11-11 23:12:13,10java,2022-11-11 23:12:17,10java,2022-11-11 23:12:09,10java,2022-11-11 23:12:20,10java,2022-11-11 23:12:22,10java,2022-11-11 23:12:23,10
- 窗口时间
- 并行度调整为1
第6集 Flink 二次兜底延迟数据处理 allowedLateness 更新数据实战
简介: Flink 二次兜底延迟数据处理 allowedLateness 更新数据实战
背景
- 超过了watermark的等待后,还有延迟数据到达怎么办?
- watermark先输出,然后配置allowedLateness 再延长时间,然后到了后更新之前的窗口数据

- 代码
xxxxxxxxxx//分组 开窗SingleOutputStreamOperator<String> sumDS = watermarkDS.keyBy(new KeySelector<Tuple3<String, String, Integer>, String>() {@Overridepublic String getKey(Tuple3<String, String, Integer> value) throws Exception {return value.f0;}})//开窗.window(TumblingEventTimeWindows.of(Time.seconds(10)))//允许 1分钟.allowedLateness(Time.minutes(1))//聚合, 方便调试拿到窗口全部数据,全窗口函数.apply();sumDS.print();
- 测试数据
xxxxxxxxxxjava,2022-11-11 23:12:07,10java,2022-11-11 23:12:11,10java,2022-11-11 23:12:08,10java,2022-11-11 23:12:13,10java,2022-11-11 23:12:23,10#延迟1分钟内,所以会输出java,2022-11-11 23:12:09,10java,2022-11-11 23:12:02,10java,2022-11-11 23:14:30,10#延迟超过1分钟,不会输出java,2022-11-11 23:12:03,10
第7集 Flink 最后的兜底延迟数据处理 测输出流实战
简介: Flink 最后的兜底延迟数据处理 测输出流实战
背景
- 超过了watermark的等待后,还有延迟数据到达怎么办?
- watermark先输出,然后配置allowedLateness 再延长时间,然后到了后更新之前的窗口数据
- 数据超过了allowedLateness 后,就丢失了吗?用侧输出流 SideOutput

编码
xxxxxxxxxxOutputTag<Tuple3<String, String,Integer>> lateData = new OutputTag<Tuple3<String, String,Integer>>("lateData"){};.window(TumblingEventTimeWindows.of(Time.seconds(10)))//允许 1分钟.allowedLateness(Time.minutes(1))//最后的兜底容忍.sideOutputLateData(lateData)//不会更新之前的窗口数据,需要代码单独写逻辑处理更新之前的数据,也可以积累后批处理sumDS.getSideOutput(lateData).print("late data");
测试数据
窗口 [23:12:00 ~ 23:12:10) | [23:12:10 ~ 23: 12:20)
触发窗口计算条件
- 窗口内有数据
- watermark >= 窗口endtime
- 即 当前计算窗口最大的事件时间 - 允许乱序延迟的时间 >= Window EndTime窗口结束时间
xxxxxxxxxxjava,2022-11-11 23:12:07,10java,2022-11-11 23:12:11,10java,2022-11-11 23:12:08,10java,2022-11-11 23:12:13,10java,2022-11-11 23:12:23,10#延迟1分钟内,所以会输出java,2022-11-11 23:12:09,10java,2022-11-11 23:12:02,10java,2022-11-11 23:14:30,10#延迟超过1分钟,不会输出,配置了sideOutPut,会在兜底输出java,2022-11-11 23:12:03,10java,2022-11-11 23:12:04,10
第8集 【面试题】Flink乱序延迟时间处理-多层保证措施介绍和归纳
简介: Flink乱序延迟时间处理-多层保证措施介绍和归纳
面试题:如何保证在需要的窗口内获得指定的数据?数据有乱序延迟
flink采用watermark 、allowedLateness() 、sideOutputLateData()三个机制来保证获取数据
watermark的作用是防止数据出现延迟乱序,允许等待一会再触发窗口计算,提前输出
allowLateness,是将窗口关闭时间再延迟一段时间.设置后就像window变大了
- 那么为什么不直接把window设置大一点呢?或者把watermark加大点?
- watermark先输出数据,allowLateness会局部修复数据并主动更新窗口的数据输出
- 这期间的迟到数据不会被丢弃,而是会触发窗口重新计算
sideOutPut是最后兜底操作,超过allowLateness后,窗口已经彻底关闭了,就会把数据放到侧输出流
- 测输出流 OutputTag tag = new OutputTag
(){}, 由于泛型查除问题,需要重写方法,加花括号
- 测输出流 OutputTag tag = new OutputTag

应用场景:实时监控平台
- 可以用watermark及时输出数据
- allowLateness 做短期的更新迟到数据
- sideOutPut做兜底更新保证数据准确性
总结Flink的机制
第一层 窗口window 的作用是从DataStream数据流里指定范围获取数据。
第二层 watermark的作用是防止数据出现乱序延迟,允许窗口等待延迟数据达到,再触发计算
第三层 allowLateness 会让窗口关闭时间再延迟一段时间, 如果还有数据达到,会局部修复数据并主动更新窗口的数据输出
第四层 sideOutPut侧输出流是最后兜底操作,在窗口已经彻底关闭后,所有过期延迟数据放到侧输出流,可以单独获取,存储到某个地方再批量更新之前的聚合的数据
注意
- Flink 默认的处理方式直接丢弃迟到的数据
- sideOutPut还可以进行分流功能
- DataStream没有getSideOutput方法,SingleOutputStreamOperator才有,
- 版本弃用API
xxxxxxxxxx新接口,`WatermarkStrategy`,`TimestampAssigner` 和 `WatermarkGenerator` 因为其对时间戳和 watermark 等重点的抽象和分离很清晰,并且还统一了周期性和标记形式的 watermark 生成方式新接口之前是用AssignerWithPeriodicWatermarks和AssignerWithPunctuatedWatermarks ,现在可以弃用了
![]() 愿景:"让编程不再难学,让技术与生活更加有趣"
愿景:"让编程不再难学,让技术与生活更加有趣"
更多架构课程请访问 xdclass.net
第十三章 新版 Flink状态State管理实战和Checkpoint讲解
第1集 Flink的状态State管理讲解和应用场景解析
简介: Flink的状态State介绍和应用场景解析
什么是State状态
- 数据流处理离不开状态管理,比如窗口聚合统计、去重、排序等
- 是一个Operator的运行的状态/历史值,是维护在内存中
- 流程:一个算子的子任务接收输入流,获取对应的状态,计算新的结果,然后把结果更新到状态里面
有状态和无状态介绍
- 无状态计算: 同个数据进到算子里面多少次,都是一样的输出,比如 filter
- 有状态计算:需要考虑历史状态,同个输入会有不同的输出,比如sum、reduce聚合操作
状态管理分类
ManagedState(用的多)
Flink管理,自动存储恢复
细分两类
Keyed State 键控状态(用的多)
- 有KeyBy才用这个,仅限用在KeyStream中,每个key都有state ,是基于KeyedStream上的状态
- 一般是用richFlatFunction,或者其他richfunction里面,在open()声明周期里面进行初始化
- ValueState、ListState、MapState等数据结构
Operator State 算子状态(用的少,部分source会用)
- ListState、UnionListState、BroadcastState等数据结构
RawState(用的少)
- 用户自己管理和维护
- 存储结构:二进制数组
State数据结构(状态值可能存在内存、磁盘、DB或者其他分布式存储中)
ValueState 简单的存储一个值(ThreadLocal / String)
- ValueState.value()
- ValueState.update(T value)
ListState 列表
- ListState.add(T value)
- ListState.get() //得到一个Iterator
MapState 映射类型
- MapState.get(key)
- MapState.put(key, value)
第2集【全网新版】Flink 1.13 的状态State后端存储讲解
简介: Flink 1.13 的状态State后端存储讲解
- 注意
xxxxxxxxxx从Flink 1.13开始,社区重新设计了其公共状态后端类,以帮助用户更好地理解本地状态存储和检查点存储的分离用户可以迁移现有应用程序以使用新 API,而不会丢失任何状态或一致性文档:https://ci.apache.org/projects/flink/flink-docs-release-1.13/docs/ops/state/state_backends/
State状态后端:存储在哪里
Flink 内置了以下这些开箱即用的 state backends :
(新版)HashMapStateBackend、EmbeddedRocksDBStateBackend
- 如果没有其他配置,系统将使用 HashMapStateBackend。
(旧版)MemoryStateBackend、FsStateBackend、RocksDBStateBackend
- 如果不设置,默认使用 MemoryStateBackend。
状态详解
HashMapStateBackend 保存数据在内部作为Java堆的对象。
键/值状态和窗口操作符持有哈希表,用于存储值、触发器等
非常快,因为每个状态访问和更新都对 Java 堆上的对象进行操作
但是状态大小受集群内可用内存的限制
场景:
- 具有大状态、长窗口、大键/值状态的作业。
- 所有高可用性设置。
EmbeddedRocksDBStateBackend 在RocksDB数据库中保存状态数据
该数据库(默认)存储在 TaskManager 本地数据目录中
与HashMapStateBackend在java存储 对象不同,数据存储为序列化的字节数组
RocksDB可以根据可用磁盘空间进行扩展,并且是唯一支持增量快照的状态后端。
但是每个状态访问和更新都需要(反)序列化并可能从磁盘读取,这导致平均性能比内存状态后端慢一个数量级
场景
- 具有非常大状态、长窗口、大键/值状态的作业。
- 所有高可用性设置
旧版
xxxxxxxxxxMemoryStateBackend(内存,不推荐在生产场景使用)FsStateBackend(文件系统上,本地文件系统、HDFS, 性能更好,常用)RocksDBStateBackend (无需担心 OOM 风险,是大部分时候的选择)配置
- 方式一:可以
flink-conf.yaml使用配置键在 中配置默认状态后端state.backend。
xxxxxxxxxx配置条目的可能值是hashmap (HashMapStateBackend)、rocksdb (EmbeddedRocksDBStateBackend)或实现状态后端工厂StateBackendFactory的类的完全限定类名#全局配置例子一# The backend that will be used to store operator state checkpointsstate.backend: hashmap# Optional, Flink will automatically default to JobManagerCheckpointStorage# when no checkpoint directory is specified.state.checkpoint-storage: jobmanager#全局配置例子二state.backend: rocksdbstate.checkpoints.dir: file:///checkpoint-dir/# Optional, Flink will automatically default to FileSystemCheckpointStorage# when a checkpoint directory is specified.state.checkpoint-storage: filesystem- 方式二:代码 单独job配置例子
xxxxxxxxxx//代码配置一StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setStateBackend(new HashMapStateBackend());env.getCheckpointConfig().setCheckpointStorage(new JobManagerCheckpointStorage());//代码配置二StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setStateBackend(new EmbeddedRocksDBStateBackend());env.getCheckpointConfig().setCheckpointStorage("file:///checkpoint-dir");//或者env.getCheckpointConfig().setCheckpointStorage(new FileSystemCheckpointStorage("file:///checkpoint-dir"));- 备注:使用 RocksDBStateBackend 需要加依赖
xxxxxxxxxx<dependency><groupId>org.apache.flink</groupId><artifactId>flink-statebackend-rocksdb_${scala.version}</artifactId><version>1.13.1</version></dependency>- 方式一:可以
第3集 Flink的状态State管理实战-订单数据统计实现MaxBy操作
简介: Flink的状态State管理实战-订单数据统计实现MaxBy操作
sum()、maxBy() 等函数底层源码也是有ValueState进行状态存储
需求:
- 根据订单进行分组,统计找出每个商品最大的订单成交额
- 不用maxBy实现,用ValueState实现
编码实战
xxxxxxxxxx/*** 使用valueState实现maxBy功能,统计分组内订单金额最高的订单** @param args*/public static void main(String[] args) throws Exception {//构建执行任务环境以及任务的启动的入口, 存储全局相关的参数StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);DataStream<String> ds = env.socketTextStream("127.0.0.1", 8888);DataStream<Tuple3<String, String, Integer>> flatMapDS = ds.flatMap(new RichFlatMapFunction<String, Tuple3<String, String, Integer>>() {@Overridepublic void flatMap(String value, Collector<Tuple3<String, String, Integer>> out) throws Exception {String[] arr = value.split(",");out.collect(Tuple3.of(arr[0], arr[1], Integer.parseInt(arr[2])));}});//一定要key by后才可以使用键控状态ValueStateSingleOutputStreamOperator<Tuple2<String, Integer>> maxVideoOrder = flatMapDS.keyBy(new KeySelector<Tuple3<String,String,Integer>, String>() {@Overridepublic String getKey(Tuple3<String, String, Integer> value) throws Exception {return value.f0;}}).map(new RichMapFunction<Tuple3<String, String, Integer>, Tuple2<String, Integer>>() {private ValueState<Integer> valueState = null;@Overridepublic void open(Configuration parameters) throws Exception {valueState = getRuntimeContext().getState(new ValueStateDescriptor<Integer>("total", Integer.class));}@Overridepublic Tuple2<String, Integer> map(Tuple3<String, String, Integer> tuple3) throws Exception {// 取出State中的最大值Integer stateMaxValue = valueState.value();Integer currentValue = tuple3.f2;if (stateMaxValue == null || currentValue > stateMaxValue) {//更新状态,把当前的作为新的最大值存到状态中valueState.update(currentValue);return Tuple2.of(tuple3.f0, currentValue);} else {//历史值更大return Tuple2.of(tuple3.f0, stateMaxValue);}}});maxVideoOrder.print();env.execute("valueState job");}
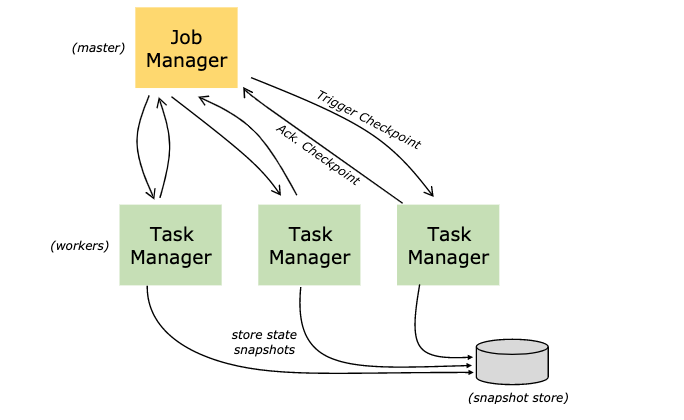
第4集 Flink的Checkpoint-SavePoint和端到端(end-to-end)状态一致性介绍
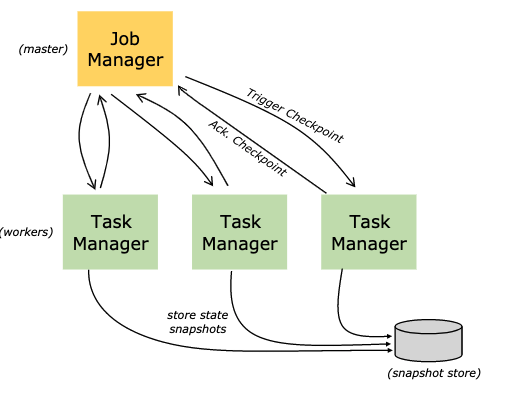
简介:Flink的Checkpoint-SavePoint和端到端状态一致性介绍
什么是Checkpoint 检查点
- Flink中所有的Operator的当前State的全局快照
- 默认情况下 checkpoint 是禁用的
- Checkpoint是把State数据定时持久化存储,防止丢失
- 手工调用checkpoint,叫 savepoint,主要是用于flink集群维护升级等
- 底层使用了Chandy-Lamport 分布式快照算法,保证数据在分布式环境下的一致性
开箱即用,Flink 捆绑了这些检查点存储类型:
- 作业管理器检查点存储 JobManagerCheckpointStorage
- 文件系统检查点存储 FileSystemCheckpointStorage
配置
xxxxxxxxxx//全局配置checkpointsstate.checkpoints.dir: hdfs:///checkpoints///作业单独配置checkpointsenv.getCheckpointConfig().setCheckpointStorage("hdfs:///checkpoints-data/");
xxxxxxxxxx//全局配置savepointstate.savepoints.dir: hdfs:///flink/savepoints
Savepoint 与 Checkpoint 的不同之处
- 类似于传统数据库中的备份与恢复日志之间的差异
- Checkpoint 的主要目的是为意外失败的作业提供【重启恢复机制】,
- Checkpoint 的生命周期由 Flink 管理,即 Flink 创建,管理和删除 Checkpoint - 无需用户交互
- Savepoint 由用户创建,拥有和删除, 主要是【升级 Flink 版本】,调整用户逻辑
- 除去概念上的差异,Checkpoint 和 Savepoint 的当前实现基本上使用相同的代码并生成相同的格式
端到端(end-to-end)状态一致性
xxxxxxxxxx数据一致性保证都是由流处理器实现的,也就是说都是在Flink流处理器内部保证的在真实应用中,了流处理器以外还包含了数据源(例如Kafka、Mysql)和输出到持久化系统(Kafka、Mysql、Hbase、CK)端到端的一致性保证,是意味着结果的正确性贯穿了整个流处理应用的各个环节,每一个组件都要保证自己的一致性。Source
- 需要外部数据源可以重置读取位置,当发生故障的时候重置偏移量到故障之前的位置
内部
- 依赖Checkpoints机制,在发生故障的时可以恢复各个环节的数据
Sink:
- 当故障恢复时,数据不会重复写入外部系统,常见的就是 幂等和事务写入(和checkpoint配合)
第5集 Flink的Checkpoint代码配置案例实战
简介:Flink的Checkpoint代码配置案例实战
- 配置
xxxxxxxxxx//两个检查点之间间隔时间,默认是0,单位毫秒env.getCheckpointConfig().setMinPauseBetweenCheckpoints(500);//Checkpoint过程中出现错误,是否让整体任务都失败,默认值为0,表示不容忍任何Checkpoint失败env.getCheckpointConfig().setTolerableCheckpointFailureNumber(5);//Checkpoint是进行失败恢复,当一个 Flink 应用程序失败终止、人为取消等时,它的 Checkpoint 就会被清除//可以配置不同策略进行操作// DELETE_ON_CANCELLATION: 当作业取消时,Checkpoint 状态信息会被删除,因此取消任务后,不能从 Checkpoint 位置进行恢复任务// RETAIN_ON_CANCELLATION(多): 当作业手动取消时,将会保留作业的 Checkpoint 状态信息,要手动清除该作业的 Checkpoint 状态信息env.getCheckpointConfig().enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);//Flink 默认提供 Extractly-Once 保证 State 的一致性,还提供了 Extractly-Once,At-Least-Once 两种模式,// 设置checkpoint的模式为EXACTLY_ONCE,也是默认的,env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);//设置checkpoint的超时时间, 如果规定时间没完成则放弃,默认是10分钟env.getCheckpointConfig().setCheckpointTimeout(60000);//设置同一时刻有多少个checkpoint可以同时执行,默认为1就行,以避免占用太多正常数据处理资源env.getCheckpointConfig().setMaxConcurrentCheckpoints(1);//设置了重启策略, 作业在失败后能自动恢复,失败后最多重启3次,每次重启间隔10senv.setRestartStrategy(RestartStrategies.fixedDelayRestart(3, 10000));
![]() 愿景:"让编程不再难学,让技术与生活更加有趣"
愿景:"让编程不再难学,让技术与生活更加有趣"
更多架构课程请访问 xdclass.net
第十四章 Flink 复杂事件处理 CEP讲解+案例实战
第1集 Flink的复杂事件处理 CEP介绍和应用场景
简介:Flink的复杂事件处理 CEP介绍和应用场景
什么是FlinkCEP
CEP全称 Complex event processing 复杂事件处理
FlinkCEP 是在 Flink 之上实现的复杂事件处理(CEP)库
擅长高吞吐、低延迟的处理,市场上有多种CEP的解决方案,例如Spark,但是Flink专门类库更方便使用
地址:https://ci.apache.org/projects/flink/flink-docs-release-1.13/docs/libs/cep/
用途
- 检测和发现无边界事件流中多个记录的关联规则,得到满足规则的复杂事件
- 允许业务定义要从输入流中提取的复杂模式序列
使用流程
- 定义pattern
- pattern应用到数据流,得到模式流
- 从模式流 获取结果
xxxxxxxxxxDataStream<Event> input = ...Pattern<Event, ?> pattern = Pattern.<Event>begin("start").where(new SimpleCondition<Event>() {@Overridepublic boolean filter(Event event) {return event.getId() == 42;}}).next("middle").subtype(SubEvent.class).where(new SimpleCondition<SubEvent>() {@Overridepublic boolean filter(SubEvent subEvent) {return subEvent.getVolume() >= 10.0;}}).followedBy("end").where(new SimpleCondition<Event>() {@Overridepublic boolean filter(Event event) {return event.getName().equals("end");}});PatternStream<Event> patternStream = CEP.pattern(input, pattern);DataStream<Alert> result = patternStream.process(new PatternProcessFunction<Event, Alert>() {@Overridepublic void processMatch(Map<String, List<Event>> pattern,Context ctx,Collector<Alert> out) throws Exception {out.collect(createAlertFrom(pattern));}});
- CEP并不包含在flink中,使用前需要自己导入
xxxxxxxxxx<dependency><groupId>org.apache.flink</groupId><artifactId>flink-cep_${scala.version}</artifactId><version>${flink.version}</version></dependency>
第2集 Flink的复杂事件处理 CEP常见概念解析
简介:Flink的复杂事件处理 CEP常见概念解析
概念
模式(Pattern):定义处理事件的规则
三种模式PatternAPI
- 个体模式(Individual Patterns):组成复杂规则的每一个单独的模式定义,就是个体模式
- 组合模式(Combining Patterns):很多个体模式组合起来,形成组合模式
- 模式组(Groups of Patterns):将一个组合模式作为条件嵌套在个体模式里,就是模式组
近邻模式
- 严格近邻:期望所有匹配事件严格地一个接一个出现,中间没有任何不匹配的事件, API是.next()
- 宽松近邻:允许中间出现不匹配的事件,API是.followedBy()
- 非确定性宽松近邻:可以忽略已经匹配的条件,API是followedByAny()
- 指定时间约束:指定模式在多长时间内匹配有效,API是within
- 如果您不希望事件类型直接跟随另一个,notNext()
- 如果您不希望事件类型介于其他两种事件类型之间,notFollowedBy()
模式分类
- 单次模式:接收一次一个事件
- 循环模式:接收一个或多个事件
其他参数
- times:指定固定的循环执行次数
- greedy:贪婪模式,尽可能多触发
- oneOrMore:指定触发一次或多次
- timesOrMore:指定触发固定以上的次数
- optional:要么不触发要么触发指定的次数
第3集 Flink的复杂事件处理 CEP案例实战-账号登录风控检测《上》
简介:Flink的复杂事件处理 CEP案例实战-账号登录风控检测《上》
需求
- 同个账号,在5秒内连续登录失败2次,则认为存在而已登录问题
- 数据格式 小D,2022-11-11 12:01:01,-1
编码
xxxxxxxxxxpublic static void main(String[] args) throws Exception {//构建执行任务环境以及任务的启动的入口, 存储全局相关的参数StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);DataStream<String> ds = env.socketTextStream("127.0.0.1", 8888);DataStream<Tuple3<String, String, Integer>> flatMapDS = ds.flatMap(new FlatMapFunction<String, Tuple3<String, String, Integer>>() {@Overridepublic void flatMap(String value, Collector<Tuple3<String, String, Integer>> out) throws Exception {String[] arr = value.split(",");out.collect(Tuple3.of(arr[0], arr[1], Integer.parseInt(arr[2])));}});SingleOutputStreamOperator<Tuple3<String, String, Integer>> watermakerDS = flatMapDS.assignTimestampsAndWatermarks(WatermarkStrategy//延迟策略去掉了延迟时间,时间是单调递增,event中的时间戳充当了水印.<Tuple3<String, String, Integer>>forMonotonousTimestamps()//生成一个延迟3s的固定水印//.<Tuple3<String, String, Integer>>forBoundedOutOfOrderness(Duration.ofSeconds(3)).withTimestampAssigner((event, timestamp) -> {//指定POJO的事件时间列return TimeUtil.strToDate(event.f1).getTime();}));KeyedStream<Tuple3<String, String, Integer>, String> keyedStream = watermakerDS.keyBy(new KeySelector<Tuple3<String, String, Integer>, String>() {@Overridepublic String getKey(Tuple3<String, String, Integer> value) throws Exception {return value.f0;}});//定义模式Pattern<Tuple3<String, String, Integer>, Tuple3<String, String, Integer>> pattern = Pattern.<Tuple3<String, String, Integer>>begin("firstTimeLogin").where(new SimpleCondition<Tuple3<String, String, Integer>>() {@Overridepublic boolean filter(Tuple3<String, String, Integer> value) throws Exception {// -1 是登录失败错误码return value.f2 == -1;}})//.times(2).within(Time.seconds(10));//不是严格近邻.next("secondTimeLogin").where(new SimpleCondition<Tuple3<String, String, Integer>>() {@Overridepublic boolean filter(Tuple3<String, String, Integer> value) throws Exception {return value.f2 == -1;}}).within(Time.seconds(5));//匹配检查PatternStream<Tuple3<String, String, Integer>> patternStream = CEP.pattern(keyedStream, pattern);SingleOutputStreamOperator<Tuple3<String, String,String>> select = patternStream.select(new PatternSelectFunction<Tuple3<String, String, Integer>, Tuple3<String, String,String>>() {@Overridepublic Tuple3<String, String,String> select(Map<String, List<Tuple3<String, String, Integer>>> map) throws Exception {Tuple3<String, String, Integer> firstLoginFail = map.get("firstTimeLogin").get(0);Tuple3<String, String, Integer> secondLoginFail = map.get("secondTimeLogin").get(0);return Tuple3.of(firstLoginFail.f0,firstLoginFail.f1,secondLoginFail.f1);}});select.print("匹配结果");env.execute("CEP job");}
第4集 Flink的复杂事件处理 CEP案例实战-账号登录风控检测《下》
简介:Flink的复杂事件处理 CEP案例实战-账号登录风控检测《下》
- 测试数据
xxxxxxxxxx小D,2022-11-11 12:01:01,-1老王,2022-11-11 12:01:10,-1老王,2022-11-11 12:01:11,-1小D,2022-11-11 12:01:13,-1老王,2022-11-11 12:01:14,-1老王,2022-11-11 12:01:15,1小D,2022-11-11 12:01:16,-1老王,2022-11-11 12:01:17,-1小D,2022-11-11 12:01:20,1
![]() 愿景:"让编程不再难学,让技术与生活更加有趣"
愿景:"让编程不再难学,让技术与生活更加有趣"
更多架构课程请访问 xdclass.net
第十五章 Flink项目打包插件讲解+部署阿里云实战
第1集 Flink服务端多种部署模式介绍
简介:Flink服务端部署多种部署模式介绍
项目都IDEA里面开发,生产环境怎么办?
Flink 部署方式是灵活,主要是对Flink计算时所需资源的管理方式不同
文档:https://ci.apache.org/projects/flink/flink-docs-release-1.13/zh/docs/deployment/overview/
Local 本地部署,直接启动进程,适合调试使用
- 直接部署启动服务
Standalone Cluster集群部署,flink自带集群模式
Hadoop YARN 计算资源统一由Hadoop YARN管理资源进行调度,按需使用提高集群的资源利用率
Kubernetes 部署
Docker部署
第2集 Flink部署云服务器介绍和相关环境准备说明
简介:Flink部署云服务器介绍和相关环境准备说明
云厂商
阿里云新用户地址(如果地址失效,联系我或者客服即可,1折)
联系客服免费领取【热门IT环境搭建视频】
阿里云服务器选购+阿里云控制台界面 课程 服务器:Linux Centos7.X
https://detail.tmall.com/item.htm?id=650488560239
- 课程前面4章是必备看,后续的选择性观看
环境问题说明
- Win7、Win8、Win10、Mac、虚拟机等等,可能存在兼容问题
- 务必使用CentOS 7 以上版本,64位系统!!!!

必备环境
- Linux服务器安装好JDK8
xxxxxxxxxxPlease specify JAVA_HOME. Either in Flink config ./conf/flink-conf.yaml or as system-wide JAVA_HOME.
第3集 新版Flink下载和Local本地模式部署Linux服务器
简介:新版Flink下载和Local本地模式部署Linux服务器
Flink下载地址
- https://flink.apache.org/zh/downloads.html
- flink版本 1.13.1(课程安装包那边有提供)
步骤
解压 tar -zxvf
目录介绍
conf
- flink-conf.yaml
xxxxxxxxxx#web ui 端口rest.port=8081#调整,我的机器是2、4、8g都有的,大家最好买4g或者8gjobmanager.memory.process.size: 1000mtaskmanager.memory.process.size: 1000mbin
- start-cluster.sh
- stop-cluster.sh
- yarn-session.sh
example
启动 bin/start-cluster.sh
停止 bin/stop-cluster.sh
查看进程 jps
- TaskManagerRunner
- StandaloneSessionClusterEntrypoint

网络安全组或者防火墙开放端口 8081
- 访问地址 http://ip:8081
第4集 Flink的local模式运行官方案例操作详解
简介:Flink的local模式运行官方案例操作详解
flink测试案例
- 创建文件
xxxxxxxxxxcd /usr/local/software/flink/examples/sourcevim xdclass_source.txtjava xdclassspringboot springcloudhtml flinkspringboot redisjava flinkkafka flinkjava springboot- bin目录运行
xxxxxxxxxx./flink run /usr/local/software/flink/examples/batch/WordCount.jar --input /usr/local/software/flink/examples/source/xdclass_source.txt --output /usr/local/software/flink/examples/source/xdclass_result.txt- 访问web UI (有个小bug,内存不够,页面访问失败则重新点击或者加大内存)
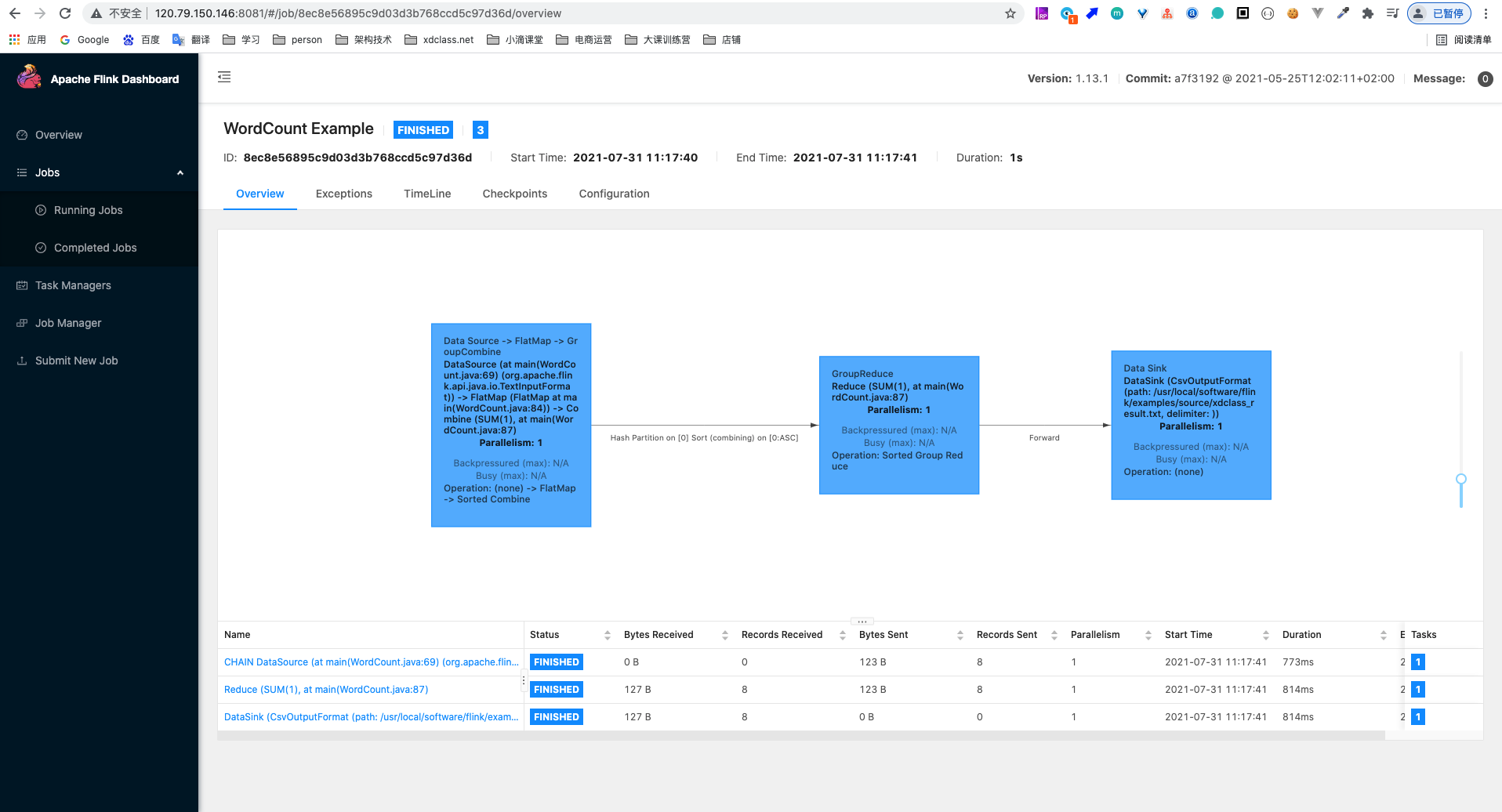
第5集 maven常用插件介绍和本地Flink项目打包
简介:maven常用插件介绍和本地Flink项目打包
- 添加打包插件
xxxxxxxxxx<build><finalName>xdclass-flink</finalName><plugins><!--默认编译版本比较低,所以用compiler插件,指定项目源码的jdk版本,编译后的jdk版本和编码,--><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-compiler-plugin</artifactId><version>3.6.1</version><configuration><source>${java.version}</source><target>${java.version}</target><encoding>${file.encoding}</encoding></configuration></plugin><!-- 添加依赖到jar包 --><!--<plugin>--><!--<artifactId>maven-assembly-plugin</artifactId>--><!--<configuration>--><!--<descriptorRefs>--><!--<descriptorRef>jar-with-dependencies</descriptorRef>--><!--</descriptorRefs>--><!--</configuration>--><!--<executions>--><!--<execution>--><!--<id>make-assembly</id>--><!--<phase>package</phase>--><!--<goals>--><!--<goal>single</goal>--><!--</goals>--><!--</execution>--><!--</executions>--><!--</plugin>--><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-shade-plugin</artifactId><version>2.3</version><executions><execution><phase>package</phase><goals><goal>shade</goal></goals></execution></executions></plugin></plugins></build>

大家的疑惑
打包插件
- maven-jar-plugin,默认的打包插件,用来打普通的jar包,需建立lib目录里来存放需要的依赖包
- maven-shade-plugin (推荐) 将依赖的jar包打包到当前jar包,成为fat JAR包,也可以防止类冲突 隔离
- maven-assembly-plugin,大数据项目用的比较多,支持自定义的打包结构,比如sql/shell等
测试插件
- maven-surefire-plugin, 用于mvn 生命周期的测试阶段的插件,通过参数设置在junit下控制测试
第6集 通过WebUI部署Flink项目到阿里云Linux运行
简介:通过WebUI部署Flink项目到阿里云Linux运行
访问WebUI
上传jar包
- 选择main入口类APP
- 提交任务查看情况
Task Solt 是指taskmanager的并发执行能力,parallelism是指taskmanager实际使用的并发能力
xxxxxxxxxxtaskmanager.numberOfTaskSlots:4假如每一个taskmanager中的分配4个TaskSlot,那有3个taskmanager一共有12个TaskSlot测试数据
xxxxxxxxxxAA,2022-11-11 12:01:01,-1BB,2022-11-11 12:01:02,1AA,2022-11-11 12:01:04,-1AA,2022-11-11 12:01:05,-1
并行度和solt的疑惑
- Task Slots 是具备的并发能力,大于 Parallelism并行度(实际用的)
- 数据流里面算子的最大并行度就是Parallelism, 2-2-2-3-1 这样的并行度,最大就是3(同个任务job里面)
![]() 愿景:"让编程不再难学,让技术与生活更加有趣"
愿景:"让编程不再难学,让技术与生活更加有趣"
更多架构课程请访问 xdclass.net
第十六章 Docker-Compose容器化部署Flink集群实战
第1集 Linux云服务器安装docker和DockerCompose环境说明
简介:Linux云服务器安装docker和DockerCompose环境说明
联系客服免费领取【热门IT环境搭建视频】
阿里云服务器选购+阿里云控制台界面 课程 服务器:Linux Centos7.X
https://detail.tmall.com/item.htm?id=650488560239
- 课程前面4章是必备看,后续的选择性观看
- Linux服务器安装:jdk8、docker、docker-compose
- 安装并运行Docker
xxxxxxxxxxyum install docker-io -ysystemctl start docker
- 启动使用Docker
xxxxxxxxxxsystemctl start docker #运行Docker守护进程systemctl stop docker #停止Docker守护进程systemctl restart docker #重启Docker守护进程
- 修改镜像仓库
xxxxxxxxxxvim /etc/docker/daemon.json#改为下面内容,然后重启docker{"debug":true,"experimental":true,"registry-mirrors":["https://pb5bklzr.mirror.aliyuncs.com","https://hub-mirror.c.163.com","https://docker.mirrors.ustc.edu.cn"]}#查看信息docker info
什么是Docker Compose容器编排
可以轻松、高效的管理容器,它是一个用于定义和运行多容器 Docker 的应用程序工具
属于容器编排工具,可以配置并启动多个容器,适合复杂业务场景
场景
- 我们使用 Docker 的时候,定义 Dockerfile 文件,然后使用 docker build、docker run 等命令操作容器。
- 微服务架构的应用系统一般包含若干个微服务,每个微服务一般都会部署多个实例,如果每个微服务都要手动启停,那么效率之低,维护量之大可想而知
问题
- 如果你用虚拟机可能存在的问题:可能本身电脑操作系统 镜像来源、虚拟机版本和系统兼容
- 直接安装Docker或者Docker Compose不成功,或者下载Yum失败,这个只能根据报错百度检索信息
- 主要原因:官方改了地址,或者之前地址失效了,不是我能控制的,百度谷歌搜索相关安装博文
常规的部署只是Docker的冰山一角,课程快速入门,如果想深入可以看我们的Docker专题【购买,便宜】
第2集 Flink多节点集群部署模式介绍延伸
简介:Flink多节点集群部署模式介绍延伸
前言知识回顾
每个 Flink 集群的作业里,都是有客户端在运行,主要是获取 Flink 应用程序的代码,将其转换为 JobGraph 并提交给 JobManager
JobManager 将工作分配到 TaskManagers 上,在那里运行实际的操作符(例如源、转换和接收器)
客户端是啥?
- 我们前面测试的 bin/flink run xxx 这个就是客户端的一种,提交任务给flink集群运行
- 或者WebUI界面那边提交任务
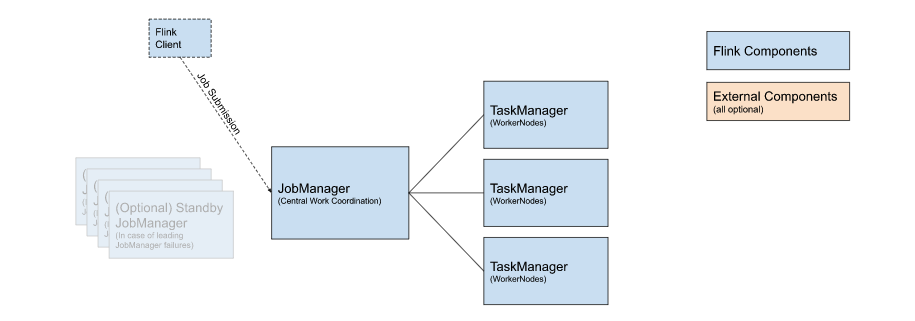
Local 本地部署,直接启动进程,适合调试使用
- 直接部署启动服务
Standalone Cluster集群部署,flink自带集群模式
Hadoop YARN 计算资源统一由Hadoop YARN管理资源进行调度,按需使用提高集群的资源利用率
Yarn集群三种模式介绍,
Session模式
- JM 负载瓶颈,main 方法在客户端执行
- 保留了Standalone的优势,需要事先申请资源,启动固定数量的JobManager和TaskManger (JobManager只有一个)
- 常驻在内存,提交到这个集群的作业可以直接运行
- Session的资源总量有限,多个job之间不是隔离的,故可能会造成资源的争用或者宕机影响
- 适合场景:对延迟非常敏感但运行时长较短的作业
Per-Job模式(Docker-Compose不支持)
- JM 负载瓶颈,main 方法在客户端执行
- 各自形成单独的Flink集群,拥有专属的JobManager和TaskManager
- 一个作业的TaskManager失败不会影响其他作业的运行, 作业完成后相关资源会被清除
- 当机器上有多个 client 时,有较高的网络负载:传输 jar 、消耗大量的 CPU 来执行 main方法
- 适合场景:规模大长时间运行的作业
Application模式(Flink 1.11版本中)
- 和Per-Job模式类似
- 主要是为了解决 Per-Job Mode 的不足,避免 带宽、CPU 的热点问题
注意:
- Docker 上的 Flink 不支持Per-Job 模式。
HA模式
- standalone cluster HA
- YARN cluster HA
- 需要JDK、zookeeper HA、flink 等程序进行构建,至少需要三个物理机。
- K8S
- 云厂商:阿里云、华为云、亚马逊云等
官方文档
第3集 DockerCompose容器化部署Flink 集群-Session Cluster模式
简介:DockerCompose容器化部署Flink 集群-Session Cluster模式
机器和配置准备
- 关闭local模式部署的flink进程
- 安装docker和docker-compose
创建docker-compose.yml 文件 Session Cluster模式
xxxxxxxxxxversion: "3.7"services:jobmanager:image: flink:scala_2.12-java8ports:- "8081:8081"command: jobmanagerenvironment:- |FLINK_PROPERTIES=jobmanager.rpc.address: jobmanagertaskmanager:image: flink:scala_2.12-java8depends_on:- jobmanagercommand: taskmanagerscale: 3environment:- |FLINK_PROPERTIES=jobmanager.rpc.address: jobmanagertaskmanager.numberOfTaskSlots: 2
- 部分同学可能这样做(也行,但是我的那个更方便)
xxxxxxxxxxversion: "3.7"services:flink-jobmanager-01:image: flink:scala_2.12-java8container_name: flink-jobmanager-01hostname: flink-jobmanager-01expose:- "6123"ports:- "8081:8081"command: jobmanagerenvironment:- JOB_MANAGER_RPC_ADDRESS=flink-jobmanager-01flink-taskmanager-01:image: flink:scala_2.12-java8container_name: flink-taskmanager-01hostname: flink-taskmanager-01expose:- "6121"- "6122"depends_on:- flink-jobmanager-01command: taskmanagerlinks:- "flink-jobmanager-01:jobmanager"environment:- JOB_MANAGER_RPC_ADDRESS=flink-jobmanager-01flink-taskmanager-02:image: flink:scala_2.12-java8container_name: flink-taskmanager-02hostname: flink-taskmanager-02expose:- "6121"- "6122"depends_on:- flink-jobmanager-01command: taskmanagerlinks:- "flink-jobmanager-01:jobmanager"environment:- JOB_MANAGER_RPC_ADDRESS=flink-jobmanager-01
- 端口说明
xxxxxxxxxxThe Web Client is on port 8081JobManager RPC port 6123TaskManagers RPC port 6122TaskManagers Data port 6121注意:expose暴露容器给link到当前容器的容器ports是暴露容器端口到宿主机端口进行映射
问题
- 内存不足 (其他程序不运行,最少也需要1核2g,建议是4或者8g)
- 网络安全组没开放端口 8081
![]() 愿景:"让编程不再难学,让技术与生活更加有趣"
愿景:"让编程不再难学,让技术与生活更加有趣"
更多架构课程请访问 xdclass.net
第十七章 Flink项目实战-实时监控告警平台案例
第1集 新版Flink综合案例实战-实时监控告警需求说明
简介:新版Flink综合案例实战-实时监控告警需求说明
案例说明
综合案例练习前面学的知识点
如果需要大型项目看 海量数据处理项目大课训练营(联系客服)
需求:公司开发一个监控告警平台(类似nginx访问日志)
- 每5秒统计过去1分钟可以统计各个接口的访问量
- 每5秒统计过去1分钟各个接口的各个状态码次数
日志来源
- 访问日志日志来源存在乱序、无效访问记录
- 要实时显示数据,可以间隔时间二次更新
- 最大允许1分钟延迟,超过后兜底保存
- 定义POJO类
xxxxxxxxxx@Data@AllArgsConstructor@NoArgsConstructorpublic class AccessLogDO {private String title;private String url;private String method;private Integer httpCode;private String body;private Date createTime;private String userId;private String city;}@Data@AllArgsConstructor@NoArgsConstructorpublic class ResultCount {private String url;private Integer code;private Long count;private String startTime;private String endTime;private String type;}
第2集 新版Flink综合案例实战-自定义Source模拟日志来源
简介:新版Flink综合案例实战-自定义Source模拟日志来源
- 自定义Source
xxxxxxxxxxpublic class AccessLogSource extends RichParallelSourceFunction<AccessLogDO> {private volatile Boolean flag = true;private Random random = new Random();//接口private static List<AccessLogDO> urlList = new ArrayList<>();static {urlList.add(new AccessLogDO("首页","/pub/api/v1/web/index_card","GET",200,"",new Date(),"",""));urlList.add(new AccessLogDO("个人信息","/pub/api/v1/web/user_info","GET",200,"",new Date(),"",""));// urlList.add(new AccessLogDO("分类列表","/pub/api/v1/web/all_category","GET",200,"",new Date(),"",""));// urlList.add(new AccessLogDO("分页视频","/pub/api/v1/web/page_video","GET",200,"",new Date(),"",""));// urlList.add(new AccessLogDO("收藏","/user/api/v1/favorite/save","POST",200,"",new Date(),"",""));// urlList.add(new AccessLogDO("下单","/user/api/v1/product/order/save","POST",200,"",new Date(),"",""));//urlList.add(new AccessLogDO("异常url","","POST",200,"",new Date(),"",""));}//状态码private static List<Integer> codeList = new ArrayList<>();static {codeList.add(200);codeList.add(200);codeList.add(502);codeList.add(403);}@Overridepublic void run(SourceContext<AccessLogDO> ctx) throws Exception {while (flag){Thread.sleep(1000);int userId = random.nextInt(50);int httpCodeNum = random.nextInt(codeList.size());int accessLogNum = random.nextInt(urlList.size());AccessLogDO accessLogDO = urlList.get(accessLogNum);accessLogDO.setHttpCode(codeList.get(httpCodeNum));accessLogDO.setUserId(userId+"");//模拟迟到数据,100秒波动//long timestamp = System.currentTimeMillis() - random.nextInt(100000);long timestamp = System.currentTimeMillis() - random.nextInt(5000);accessLogDO.setCreateTime(new Date(timestamp));System.out.println("产生:"+accessLogDO.getTitle()+",状态:"+accessLogDO.getHttpCode()+", 时间:"+ TimeUtil.format(accessLogDO.getCreateTime()));ctx.collect(accessLogDO);}}@Overridepublic void cancel() {flag = false;}}
第3集 新版Flink综合案例实战-过滤-分组-开窗-分配Watermark
简介:新版Flink综合案例实战-过滤-分组-开窗-分配Watermark
- 代码
xxxxxxxxxxpublic static void main(String[] args) throws Exception {//构建执行任务环境以及任务的启动的入口, 存储全局相关的参数StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);//java,2022-11-11 09-10-10,15DataStream<AccessLogDO> ds = env.addSource(new AccessLogSource());SingleOutputStreamOperator<AccessLogDO> filterDS = ds.filter(new FilterFunction<AccessLogDO>() {@Overridepublic boolean filter(AccessLogDO value) throws Exception {return StringUtils.isNotBlank(value.getUrl());}});//指定watermarkSingleOutputStreamOperator<AccessLogDO> watermarkDS = filterDS.assignTimestampsAndWatermarks(WatermarkStrategy//指定允许乱序延迟的最大时间 3 秒.<AccessLogDO>forBoundedOutOfOrderness(Duration.ofSeconds(3))//指定POJO事件时间列,毫秒.withTimestampAssigner((event, timestamp) -> event.getCreateTime().getTime()));//最后的兜底数据OutputTag<AccessLogDO> lateData = new OutputTag<AccessLogDO>("lateDataLog"){};//分组KeyedStream<AccessLogDO, String> keyedStream = watermarkDS.keyBy(new KeySelector<AccessLogDO, String>() {@Overridepublic String getKey(AccessLogDO value) throws Exception {return value.getUrl();}});SingleOutputStreamOperator<ResultCount> tenMinPV = keyedStream//开窗.window(SlidingEventTimeWindows.of(Time.seconds(60), Time.seconds(5)))//允许1分钟延迟.allowedLateness(Time.minutes(1)).sideOutputLateData(lateData);
第4集 新版Flink综合案例实战-增量聚合统计进阶应用实战
简介:新版Flink综合案例实战-增量聚合统计进阶应用实战
- 增量聚合统计
xxxxxxxxxx.aggregate(new AggregateFunction<AccessLogDO, Long, Long>() {@Overridepublic Long createAccumulator() {return 0L;}@Overridepublic Long add(AccessLogDO value, Long accumulator) {return accumulator + 1;}@Overridepublic Long getResult(Long accumulator) {return accumulator;}@Overridepublic Long merge(Long a, Long b) {return a + b;}}, new ProcessWindowFunction<Long, ResultCount, String, TimeWindow>() {@Overridepublic void process(String value, Context context, Iterable<Long> elements, Collector<ResultCount> out) throws Exception {ResultCount resultCount = new ResultCount();resultCount.setUrl(value);resultCount.setType("每5秒统计近1分接口PV");resultCount.setStartTime(TimeUtil.format(context.window().getStart()));resultCount.setEndTime(TimeUtil.format(context.window().getEnd()));long total = elements.iterator().next();resultCount.setCount(total);out.collect(resultCount);}});
ProcessWindowFunction 方法说明
- 一次性迭代整个窗口里的所有元素,通过Context,可以获取到事件、窗口和状态信息
- 可以和ReduceFunction, AggregateFunction 来做增量计算
- 在Agg方法做第2个参数 ,windowFunction 会把每个 key 的窗口聚合后的结果带上 上下文信息进行输出
- 之前ProcessWindowFunction是获取整个窗口的全部元素,在agg方法里面是获取聚合后的结果,一个元素
xxxxxxxxxxaggregate( AggregateFunction<T, ACC, V> aggFunction,ProcessWindowFunction<V, R, K, W> windowFunction )
第5集 新版Flink综合案例实战-滑动统计接口访问PV验证实战+乱序验证
简介:新版Flink综合案例实战-滑动统计各个接口的PV验证实战+乱序验证
- 验证数据
- 模拟迟到数据-二次更新效果
第6集 新版Flink综合案例实战-多接口-多状态码统计实战
简介:新版Flink综合案例实战--多接口-多状态码统计实战
- 多个分组字段
xxxxxxxxxxpublic static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);DataStreamSource<AccessLogDO> ds = env.addSource(new AccessLogSource());//过滤SingleOutputStreamOperator<AccessLogDO> filterDS = ds.filter(new FilterFunction<AccessLogDO>() {@Overridepublic boolean filter(AccessLogDO value) throws Exception {return StringUtils.isNotBlank(value.getUrl());}});//指定watermarkSingleOutputStreamOperator<AccessLogDO> watermarkDS = filterDS.assignTimestampsAndWatermarks(WatermarkStrategy.<AccessLogDO>forBoundedOutOfOrderness(Duration.ofSeconds(3)).withTimestampAssigner((event, timestamp) -> event.getCreateTime().getTime()));//最后兜底数据OutputTag<AccessLogDO> lateData = new OutputTag<AccessLogDO>("lateDataLog") {};//多个字段分组KeyedStream<AccessLogDO, Tuple2<String, Integer>> keyedStream = watermarkDS.keyBy(new KeySelector<AccessLogDO, Tuple2<String, Integer>>() {@Overridepublic Tuple2<String, Integer> getKey(AccessLogDO value) throws Exception {return Tuple2.of(value.getUrl(),value.getHttpCode());}});//开窗SingleOutputStreamOperator<ResultCount> aggregateDS = keyedStream.window(SlidingEventTimeWindows.of(Time.seconds(60), Time.seconds(5))).allowedLateness(Time.minutes(1)).sideOutputLateData(lateData).aggregate(new AggregateFunction<AccessLogDO, Long, Long>() {@Overridepublic Long createAccumulator() {return 0L;}@Overridepublic Long add(AccessLogDO value, Long accumulator) {return accumulator+1;}@Overridepublic Long getResult(Long accumulator) {return accumulator;}@Overridepublic Long merge(Long a, Long b) {return a+b;}}, new ProcessWindowFunction<Long, ResultCount, Tuple2<String, Integer>, TimeWindow>() {@Overridepublic void process(Tuple2<String, Integer> value, Context context, Iterable<Long> elements, Collector<ResultCount> out) throws Exception {ResultCount resultCount = new ResultCount();resultCount.setUrl(value.f0);resultCount.setHttpCode(value.f1);long total = elements.iterator().next();resultCount.setCount(total);resultCount.setStartTime(TimeUtil.format(context.window().getStart()));resultCount.setEndTime(TimeUtil.format(context.window().getEnd()));out.collect(resultCount);}});aggregateDS.print("接口状态码");aggregateDS.getSideOutput(lateData).print("late data");env.execute("XdclassMonitorApp");}
- 聚合统计测试
第7集 新版Flink综合案例实战-Flink CEP 接口状态码监控告警
简介:新版Flink综合案例实战-Flink CEP接口监控告警
需求
- 每30秒统计,过去1分钟,各个接口的各个状态码次数,1分钟内超过5次则告警
CEP 乱序延迟问题
xxxxxxxxxxFlink CEP会将事件进行缓存,在相应的watermark到底之后,Flink CEP将缓存中的事件按照事件时间进行升序排序,然后再进行的模式匹配。当watermark到达时,处理该缓冲区中事件时间小于watermark时间的所有数据。时间小于上次的watermark的时间就是迟到的数据,迟到的数据需要用侧输出流处理
![]() 愿景:"让编程不再难学,让技术与生活更加有趣"
愿景:"让编程不再难学,让技术与生活更加有趣"
更多架构课程请访问 xdclass.net
第十八章 新一代Flink流式计算课程总结和海量数据大课介绍
第1集 新版Flink课程总结归纳和接下去的安排
简介:新版Flink课程总结归纳和接下去的安排
课程总结
- Source
- Transformation
- Sink
特性
- Window
- Watermark
- 窗口函数
- CEP
- State和Checkpoint

Flink进阶
- Flink内存管理和优化、Blink、SQL、Table API 、容错、HA、新特性
- 多流连接Join、触发器、定时器、通信组件Akka/RPC原理、JobGraph流程
大数据技术栈
- Javase【上线】
- Idea+maven+git【上线】
- Linux【上线】
- Mysql【上线】
- Javaweb【上线】
- Springboot【上线】
- Redis6.X【上线】
- Kakfa【上线】
- ElasticSearch【上线】
- ELK体系
- Hadoop生态【上线】
- Zookeeper【上线】
- Flink【上线】
- Hive
- Flume【上线】
- Shell【上线】
- Scala
- Spark生态
- Docker【上线】
- Hbase【上线】
- Zabbix监控
- Azkaban任务调度
- Canal【上线】
- Python【上线】
- ClickHouse
- 阿里云ODPS+DataV
- SpringCloud微服务【上线】
- 海量数据处理项目大课训练营【上线】
- 企业数据中台+DaaS+PaaS
大课训练营 -笔记查看(不对外提供,【原创资料】)
给个学习建议,大课推出的目的,也是很多同学需要这个
项目大课训练营
海量数据分库分表项目大课训练营
- SpringCloudAlibaba+Redis6.X+Flink+Kafka+Shardingsphere+ClickHouse|Hbase|ES
大数据中台建设大课训练营
...更多
- 记得加我微信+进技术交流群(内推、技术分享、安装包等)
第2集 架构师成长路线- 如何选择IT技术人的职场充电站
简介:小滴课堂架构师学习路线和大课训练营介绍
小滴课堂-每个技术栈课程不贵,提升自己技术能力 + 不浪费时间 + 涨薪,是超过N倍的收益
小滴课堂永久会员 & 小滴课堂年度会员
适合IT后端人员,零基础就业、在职充电、架构师学习路线-专题技术方向
- 包括业界主流技术栈,前端、后端、测试、架构等等课程,接近上百套视频,深度+广度
- 包括 从零基础到就业班,高级工程师、技术负责人、架构师技术栈 全套学习路线
- 永久会员可以观看全部专题IT技术,作为一个终生学习平台,每个月更新多套视频
- 可以获取最新路线图,有你想学的多数主流技术栈,持续更新!!!
学后水平:一线城市 15~25k
适合人员:校招、应届生、培训机构出、工作1~10年的同学都适合

学到技术,涨薪是关键,付出肯定会有收获,未来 一定是持续学习的人
我也在学习每年参加各种技术沙⻰和内部分享会投 入超过10万+,但是我认为是值的,且带来的收益更 大
大课综合训练营
适合用于专项拔高,适合有一定工作经验的同学,架构师方向发展的训练营,包括多个方向
综合项目大课训练营
海量数据分库分表大课训练营
架构解决方案大课训练营
全链路性能优化大课训练营
安全攻防大课训练营
数据分析大课训练营
算法刷题大课训练营
一对一辅导

技术人的导航站(涵盖我们主流的技术网站、社区、工具等等,即将上线)
- 地址:open1024.com
- 地址:xdclass.net
小滴课堂,愿景:让编程不在难学,让技术与生活更加有趣
相信我们,这个是可以让你学习更加轻松的平台,里面的课程绝对会让你技术不断提升
欢迎加小D讲师的微信: xdclass-lw
我们官方网站:https://xdclass.net
千人IT技术交流QQ群: 718617859
重点来啦:加讲师微信 免费赠送你干货文档大集合,包含前端,后端,测试,大数据,运维主流技术文档(持续更新)
https://mp.weixin.qq.com/s/qYnjcDYGFDQorWmSfE7lpQ